- Published at
Bài toán đồng thuận trong hệ thống phân tán và thuật toán Raft

Giới thiệu về bài toán đồng thuận và thuật toán Raft
Table of Contents
- Bài toán đồng thuận
- Bài toán các vị tướng Byzantine (Byzantine generals problem)
- Vấn đề với hệ thống phân tán
- Thuật toán đồng thuận
- Cách thuật toán đồng thuận hoạt động
- Các cột mốc lịch sử
- Raft: Vị cứu tinh mới
- Kiến trúc của Raft
- Một vài thuật ngữ trong Raft
- State
- Term
- Log
- Request Type
- Phân tích cách hoạt động của thuật toán Raft
- Bầu chọn Leader
- Log replication
- Tổng kết
- Tham khảo
Bài toán đồng thuận
Bài toán các vị tướng Byzantine (Byzantine generals problem)
Một bài toán lý thuyết trò chơi được mô tả như sau:
- Quân đội Byzantine được chia thành nhiều tiểu đoàn, đứng đầu là một vị tướng chỉ huy.
- Các tướng liên lạc với nhau qua thư để thống nhất một kế hoạch hành động chung nhằm phối hợp và tấn công từ mọi phía để đạt được thành công.
- Tuy nhiên, sẽ có những kẻ phá hoại bằng cách chặn thư hoặc những tướng phản bội thay đổi nội dung thư nhằm phá hủy kế hoạch.
Mục đích của bài toán này là làm thế nào để tất cả các vị tướng trung thành đều đạt được thỏa thuận mà những kẻ phá hoại hay tướng phản bội không can thiệp được vào kế hoạch chung của họ.
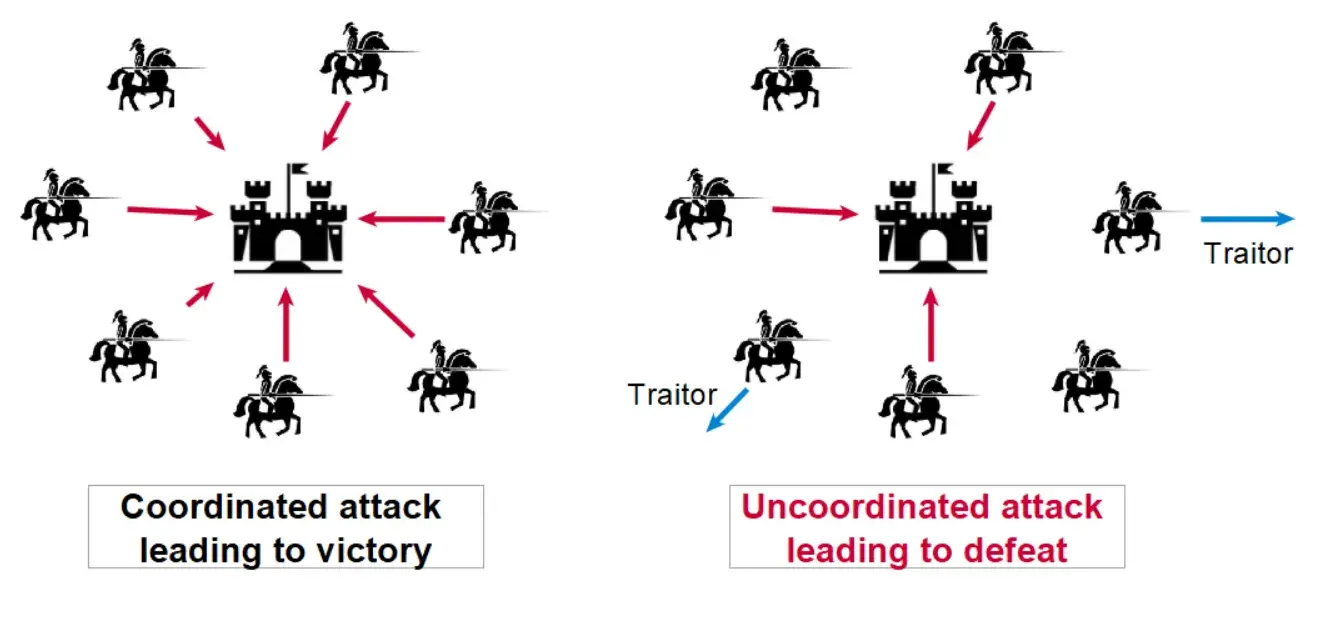
Vấn đề với hệ thống phân tán
Từ bài toán các vị tướng ở trên, ta có thể thấy có sự giống nhau trong hệ thống phân tán như sau:
- Các vị tướng là những hệ thống.
- Bức thư là thông tin muốn truyền tải.
Vậy những trường hợp trong quá trình gửi nhận thông tin có thể xảy ra:
- Thất lạc đường truyền, không tới được hệ thống khác.
- Nhận được thông tin rất trễ với thời gian là bất kì.
- Không đúng thứ tự thông tin nhận được.
- Có thể bị gửi sai hoặc nội dung bị thay đổi do các yếu tố trong hệ thống gây nên lỗi.
- …
Có thể thấy, để giải quyết được bài toán đồng thuận, ta sẽ cần phải giải quyết rất nhiều vấn đề nhỏ liên quan đến bài toán đó. Vì vậy, bài toán đồng thuận luôn mà một trong những bài toán kinh điển xuất hiện trong các hệ thống phân tán. Ví dụ như Kafka sử dụng ZooKeeper với ZooKeeper Atomic Broadcast protocol (ZAB - một biến thể của Paxos) hay Kubernetes sử dụng etcd với thuật toán Raft để đảm bảo đồng thuận cho toàn bộ hệ thống.
Thuật toán đồng thuận
Là một tiến trình trong computer science được sử dụng trong hệ thống phân tán và công nghệ blockchain để đảm bảo rằng tất cả các thành viên hoặc các node trong một network đều đồng ý về một giá trị dữ liệu hay trạng thái duy nhất, ngay cả khi giá trị đó có lỗi hoặc hành vi đó độc hại. Thuật toán này được thiết kế để đạt được độ tin cậy (reliability), độ nhất quán (consistency) và khả năng chịu lỗi (fault-tolerance).
Có 4 tính chất quan trọng của thuật toán đồng thuận:
- Agreement: Tất cả các node/member không bị lỗi phải cùng đồng ý chung về một giá trị
- Validity: Nếu tất cả các node/member không bị lỗi đề xuất cùng một giá trị, thì bất kỳ quyết định nào được đưa ra phải bao gồm giá trị đó.
- Termination: Quá trình đồng thuận phải kết thúc, và tất cả các node/member không bị lỗi phải quyết định một giá trị.
- Fault-tolerance: Thuật toán phải hoạt động chính xác ngay cả khi một số node/member gặp lỗi hoặc hành động độc hại.
Bên cạnh đó, một định lý quan trọng trong hệ thống phân tán được gọi là FLP-Impossibility của 3 tác giả Fischer, Lynch và Paterson phát biểu vào năm 1985 có nội dung như sau:
Trong hệ thống mạng bất đồng bộ, khi các tin nhắn có thể nhận trễ vô thời hạn nhưng không bao giờ thất lạc, sẽ không tồn tại một thuật toán đồng thuận nào đảm bảo kết thúc trong mọi khả năng có thể thực thi, với mọi cấu hình ban đầu khi tồn tại ít nhất một máy tính bị lỗi-và-dừng-hẳn (crash-stop model).
Cách thuật toán đồng thuận hoạt động
- Đề xuất một giá trị: Các node/member đề xuất giá trị dựa trên local data hoặc các transaction mà nó nhận được.
- Bỏ phiếu: Các node/member bỏ phiếu trên giá trị đã đề xuất. Quá trình voting có thể bao gồm nhiều vòng.
- Đồng ý: Các node/member giao tiếp với nhau để đạt được sự đồng ý về một giá trị duy nhất dựa trên các phiếu bầu.
- Quyết định: Khi đã đạt được sự đồng thuận. Tất cả các node/member cam kết giá trị đã đồng ý và tiếp tục với quyết định đó
Các cột mốc lịch sử
Từ sau định lý FLP-Impossibility được phát biểu, nó đã thay đổi hoàn toàn góc nhìn khi thiết kế thuật toán đồng thuận. Các nghiên cứu mới bắt đầu tập trung làm rõ mô hình phù hợp hơn với điều kiện thực tế, từ đó đưa ra thuật toán đồng thuận thỏa mãn được mô hình đó.
Bốn năm sau (1989), Lesie Lamport đưa ra báo cáo đầu tiên về thuật toán Paxos - một trong những thuật toán đồng thuận đầu tiên và phổ biến vẫn còn được sử dụng đến hiện nay. Paper đầu tiên ra mắt khiến nhiều nhà khoa học khó hiểu được những gì mà Paxos muốn truyền đạt vì nó đan xen giữa lý thuyết và thực tế quá nhiều. Mười hai năm sau (2001), sau khi đã viết lại Paxos với cách trình bày dễ hiểu hơn, paper mới của Lesie Lamport vẫn còn mang nhiều tính lý thuyết khiến cho việc hiện thực hoá Paxos sau này đều có những điểm khác biệt.
Mười hai năm sau đó (2013), paper về Raft lần đầu được công bố. Paper nói rằng thuật toán mới đơn giản và dễ hiểu, phù hợp cho việc học và nghiên cứu hơn so với Paxos. Vì vậy, Raft trở thành một trong những thuật toán dùng trong những bài toán đồng thuận phổ biến hiện nay
Raft: Vị cứu tinh mới
Raft - [R]ealiable, Replicated, Redundant, [A]nd [F]ault-[T]olerance là thuật toán đồng thuận được công bố vào năm 2013 được thiết kế để có thể dễ dàng hiểu được. Nó tương đương với Paxos về khả năng chịu lỗi. Điểm khác biệt là nó được phân tách thành các bài toán con tương đối độc lập và nó giải quyết rõ ràng tất cả các phần chính cần thiết cho các hệ thống thực tế.
Các giả thiết khi thiết kế thuật toán:
- Mô hình mạng: xây dựng trên nền mạng đồng bộ ảo (virtual synchrony) - chạy lần lượt qua từng vòng, có timeout cho mỗi request
- Mô hình chịu lỗi: có thể chịu được crash-recovery nhưng không chể chịu được lỗi Byzantine.
- Gói tin gửi đi có thể bị trùng lặp, mất hoặc đảo thứ tự.
Kiến trúc của Raft
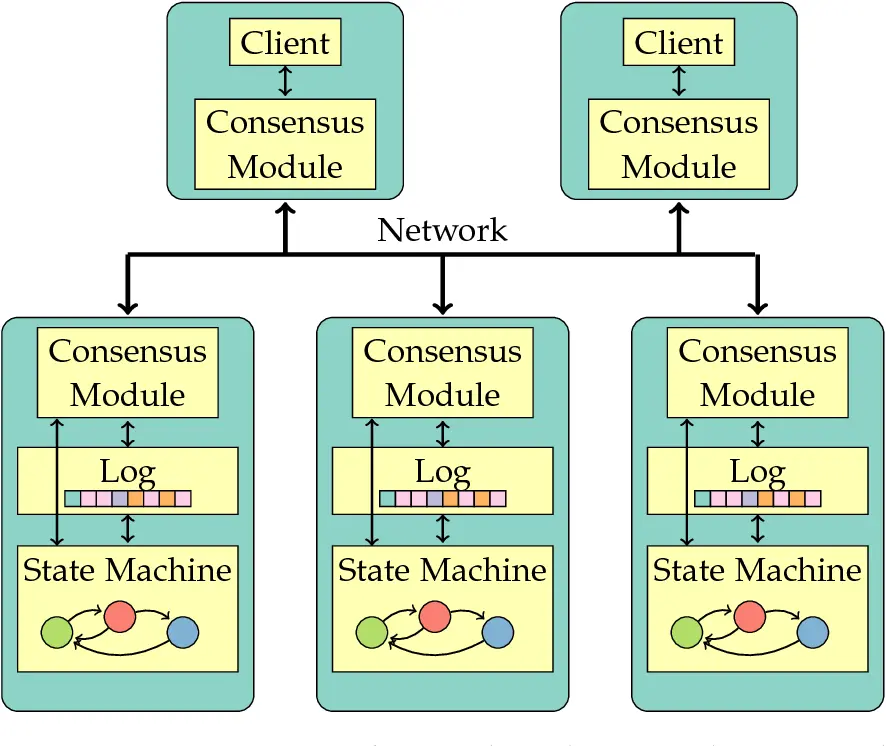
- Hệ thống bao gồm nhiều node và giao tiếp với nhau qua giao thức RPC.
- Mỗi node gồm 2 thành phần chính:
- Finite State Machine (FSM) để chứa trạng thái hiện tại của hệ thống (thường là key-value database)
- Raft module.
- Raft sử dụng Quorum (số bầu chọn tối thiểu giữa các node để một thao tác được thông qua) là [N/2] + 1 (quá bán) và thường được triển khai với số node là lẻ để luôn đảm bảo số lượng vote áp đảo với phần còn lại (VD: 5 thì cần tối thiểu 3 vote, 7 thì cần tối thiểu 4 vote).
- Có một node đóng vai trò là Leader và các node còn lại là Follower. Chỉ có node Leader mới được quyền trả lời cho người dùng. Tuy nhiên, sẽ có trường hợp có nhiều hơn một node nghĩ rằng mình là Leader. Nhưng với Quorum đã là [N/2] + 1, Raft đã đảm bảo việc không có nhiều hơn một node ngoài node Leader tại một thời điểm bất kì có khả năng trả lời người dùng.
Trong trường hợp bình thường khi người dùng gửi một request ghi tới node Leader, quy trình được thực thi sẽ là:
- API gọi xuống Raft module.
- Raft module sẽ append request vào log module, sau đó gửi request ra toàn bộ mạng.
- Leader đồng thời sẽ chờ quá bán “đồng ý” từ các máy tính trong mạng (gồm cả Leader) sau đó trả về FSM. FSM sẽ cập nhật bản ghi và trả kết quả cho người dùng.
Một vài thuật ngữ trong Raft
State
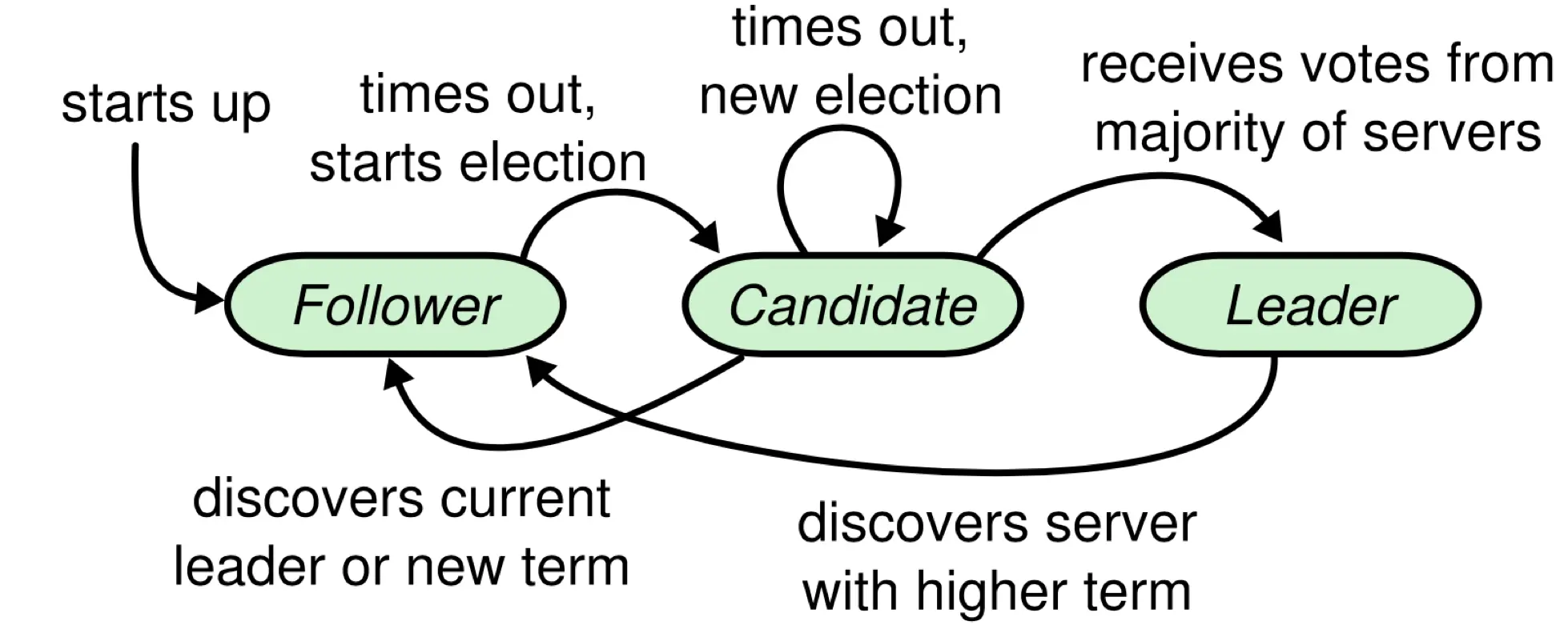
- Follower: chỉ giữ nhiệm vụ trả lời lại các lời gọi RPC trong mạng và không được phép trả lời request từ phía người dùng.
- Candidate: là trạng thái trung gian do Follower chuyển thành và cố gắng trở thành Leader.
- Leader: là node chủ động trong cluster. Leader sẽ nhận và xử lý request từ người dùng và replicate log qua các node khác.
Term
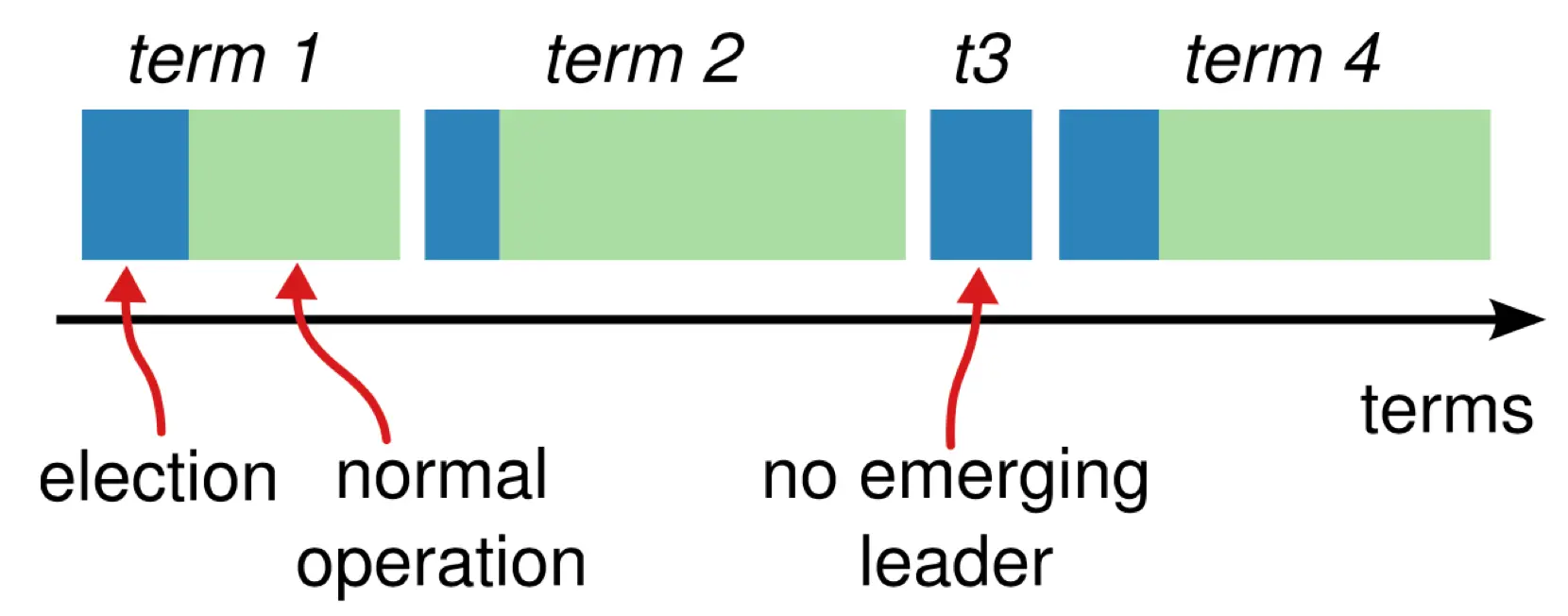
Term là số tự nhiên, đánh số liên tục, đóng vai trò như logical timestamp. Chỉ có tối đa một Leader cho mỗi term. Thông tin về term luôn được trao đổi giữa các server mỗi khi gửi nhận message.
Lưu ý: Thuật toán Raft sử dụng Term bằng 1 là số khởi tạo.
Log
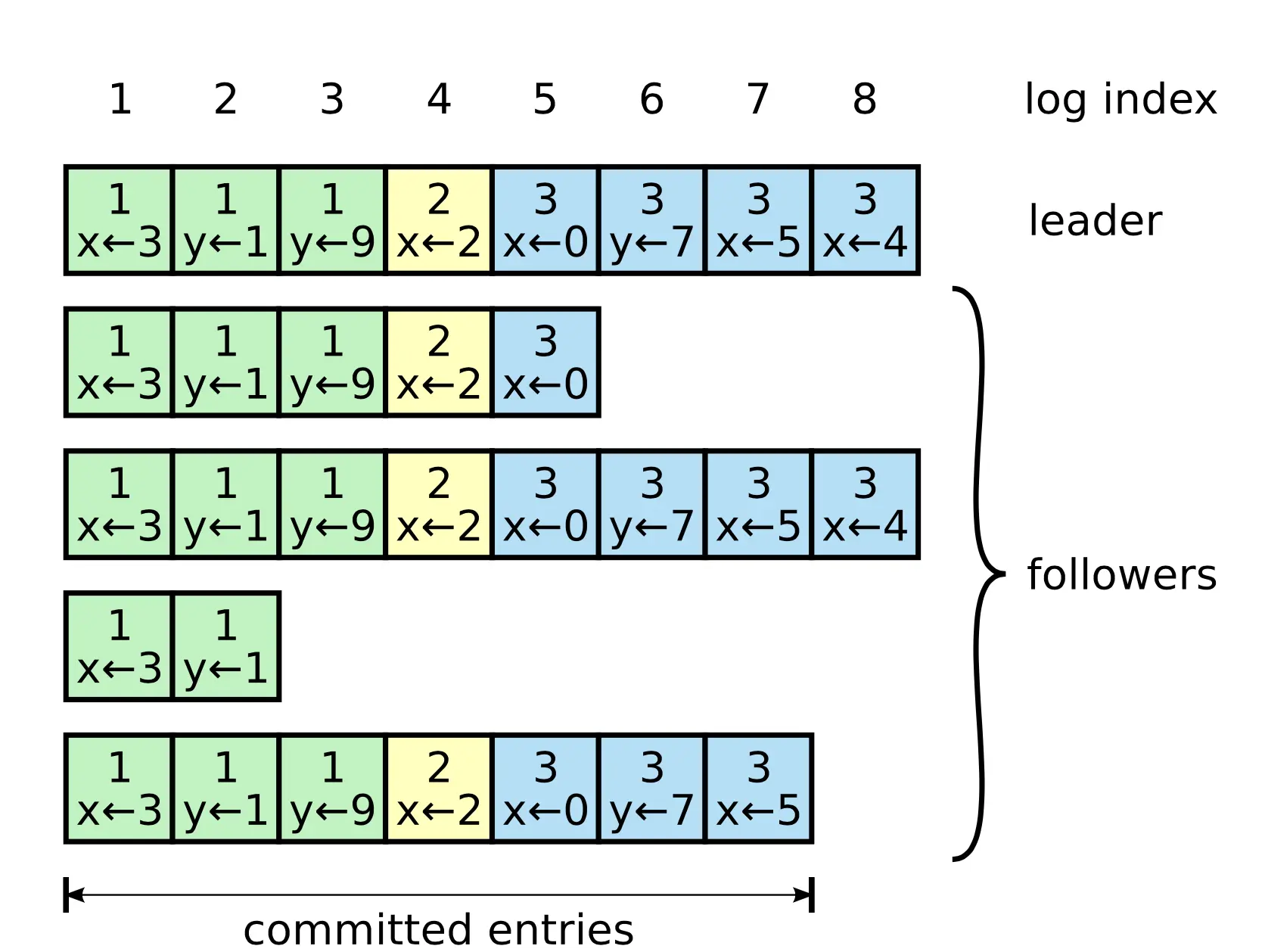
Log bao gồm các entry được đánh số tuần tự, gồm có các khái niệm:
- Log entry:
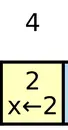
Log entry - Bao gồm 3 thành phần là data + index + term. Log entry mới luôn được ghi nối vào hệ thống.
- Log entry sẽ được lưu vào ổ đĩa ngay khi chèn vào mảng. Do vậy, hệ thống sẽ không bị mất dữ liệu khi xảy ra tình trạng crash.
- 2 log entry giữa 2 node được gọi là đồng nhất (identical) khi và chỉ khi data, index và term của chúng phải giống nhau từng đôi một. Vậy nên ta chỉ cần so sánh index + term giữa 2 log entry giống nhau thì chúng có cùng data.
- Log index: tương tự như array index; tăng dần đều một đơn vị mỗi khi thêm một log entry vào mảng trên mỗi node. Bắt đầu từ 1 (theo paper).
- Committed entry: khi một log entry được gửi thành công trên quá bán node (bao gồm chính nó), log entry này sẽ được chuyển sang trạng thái committed. Khi log entry chuyển sang trạng thái committed, ta có thể an toàn update vào FSM và trả về cho client.
Request Type
Chỉ có 2 dạng request:
- RequestVote: dùng để bầu chọn Leader.
- AppendEntries: được sử dụng trong 2 trường hợp
- Giao thức heartbeat. Khi đó, mảng các log cần replicate là empty
- Replicate log: thêm mảng các log entry cần replicate qua các Follower.
Phân tích cách hoạt động của thuật toán Raft
Có 2 phần chính:
- Bầu chọn Leader
- Log replication
Ở đây mình sử dụng Raft Visualization từ trang chủ của Raft. Các bạn có thể thử tại đây
Bầu chọn Leader
Quá trình bầu chọn có thể mô tả như sau:
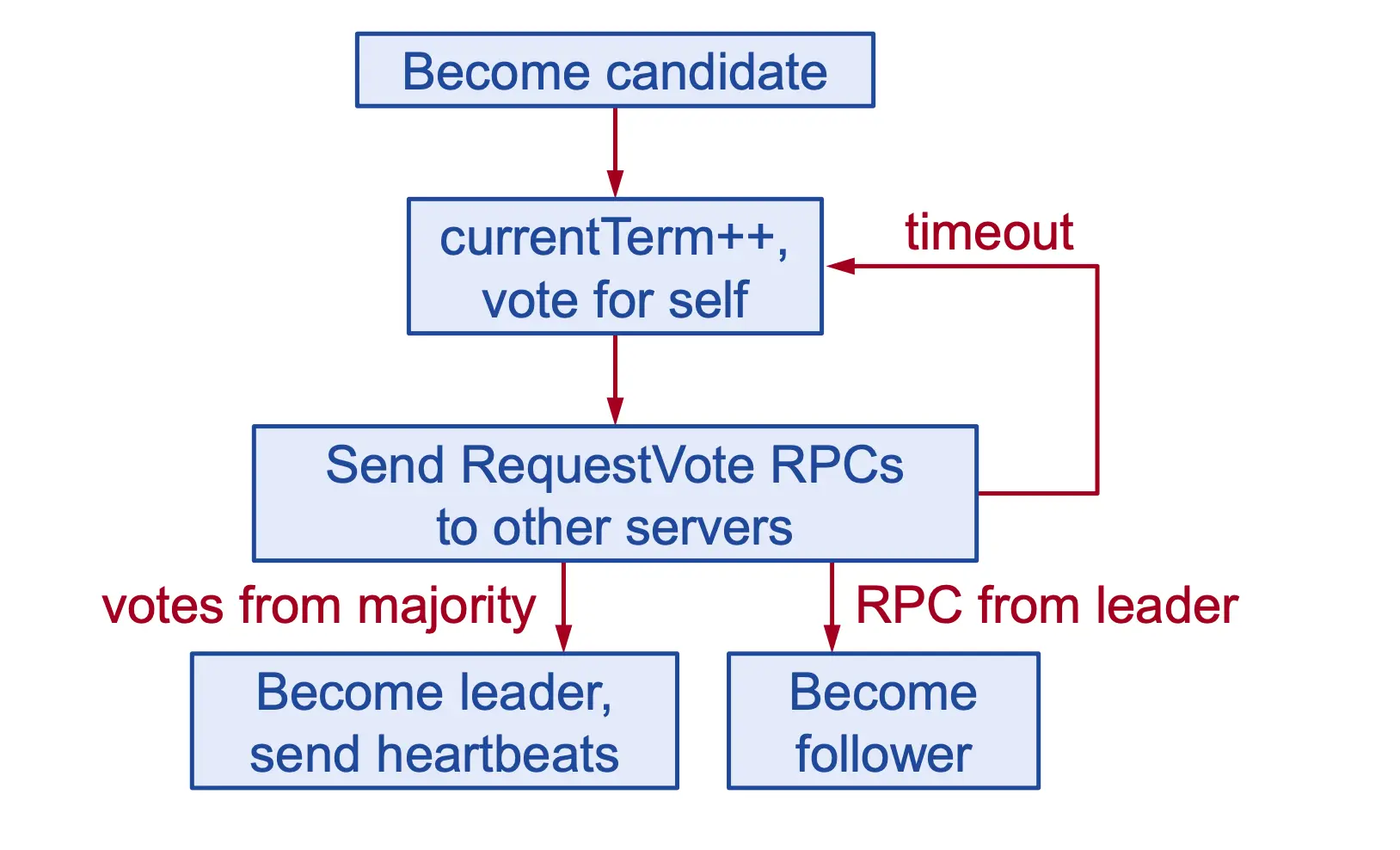
Raft sử dụng cơ chế heartbeat để trigger việc bầu chọn Leader. Khi hệ thống khởi động, các node sẽ bắt đầu ở trạng thái Follower. Leader lúc này sẽ gửi định kì heartbeat đến tất cả các Follower để duy trì vị thế. Sau một thời gian timeout khi không nhận được tín hiệu từ Leader, nó sẽ cho rằng hiện tại đang không có Leader nào khả thi và sẽ tiến hành 1 cuộc bầu cử mới để chọn ra Leader.
Có 2 giai đoạn chính trong quá trình bầu cử như sau:
Giai đoạn 1: Bắt đầu bầu cử.
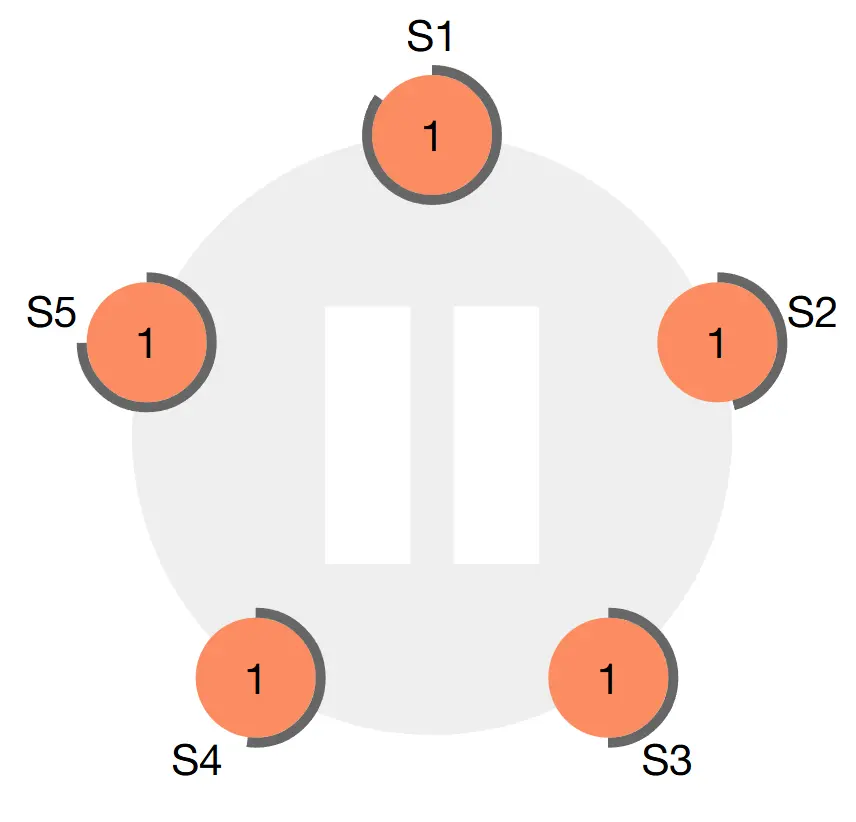
-
Follower tăng term lên 1 và chuyển mình sang trạng thái Candidate. Sau đó nó tự bầu chính nó rồi gửi
RequestVotecho toàn bộ các node khác trong hệ thống.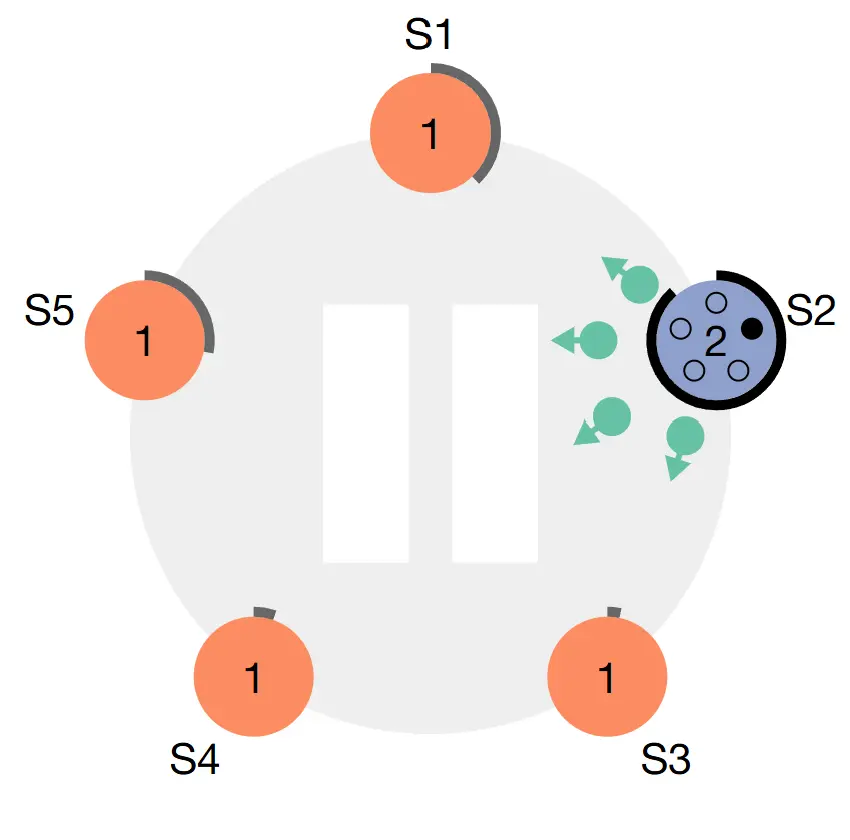
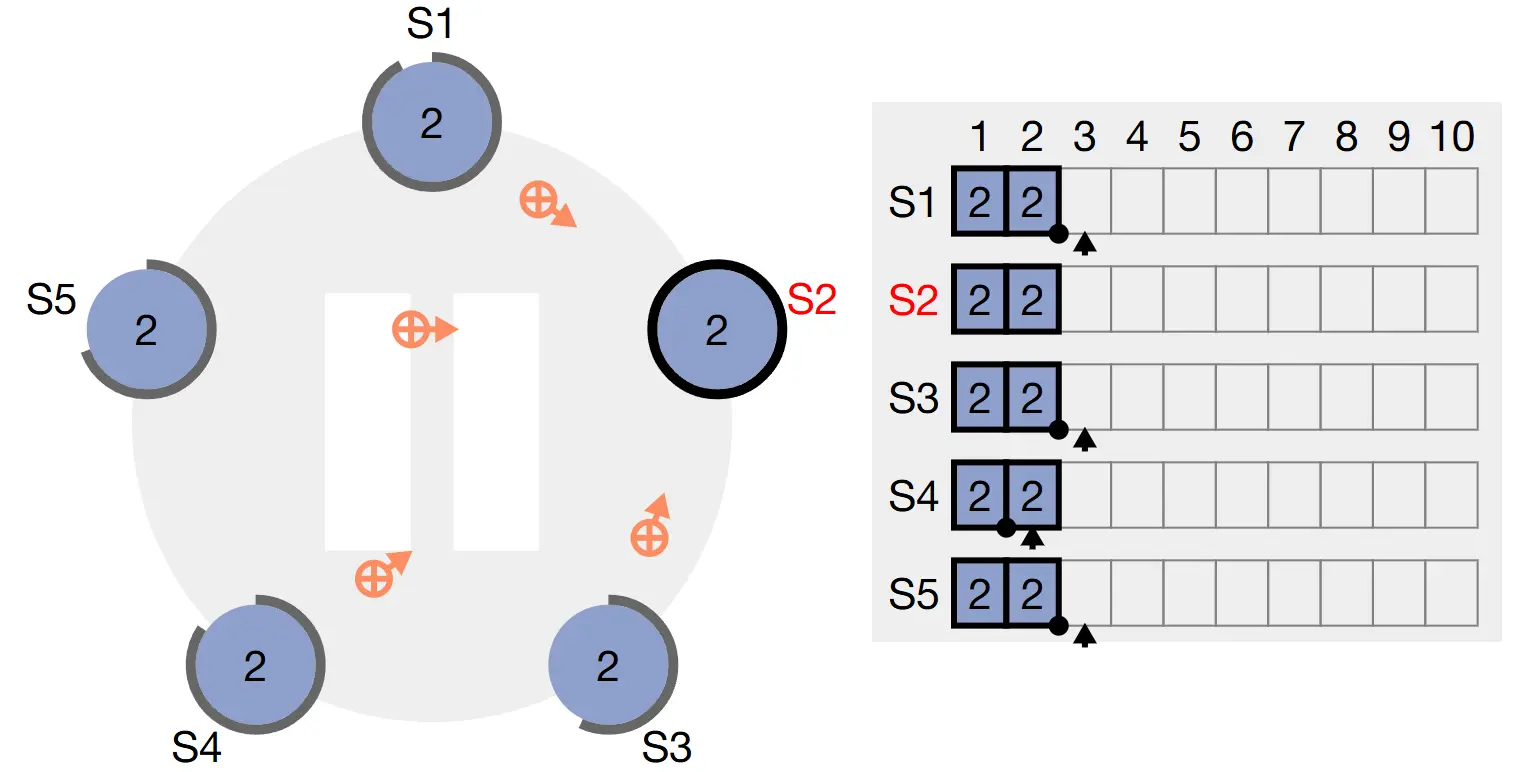
Ví dụ S2 timeout trước rồi chuyển mình sang Candidate, sau đó gửi request đến các node còn lại -
Các node khác trong hệ thống khi nhận được request RequestVote sẽ kiểm tra các điều kiện để xem Candidate có thể trở thành Leader dược hay không. Cụ thể:
- Term của Candidate phải cao hơn term hiện tại để tránh tình trạng RequestVote từ một Candidate rất cũ trong quá khứ.
- Log của Candidate phải tân thời (up-to-date) hơn log của node hiện tại.
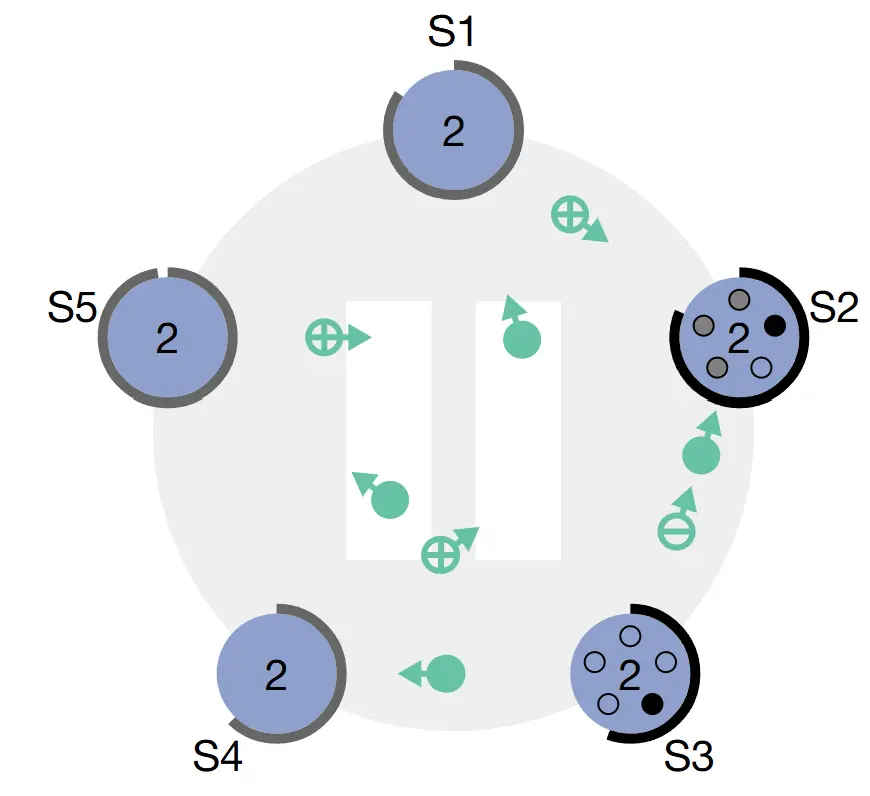
S3 trở thành Candidate trước khi nhận được RequestVote từ S2, ta có thể thấy S3 cũng đồng thời gửi RequestVote và không bỏ phiếu cho S2
Giai đoạn 2: Trong quá trình chờ bầu cử, candiate nhận được RequestVote từ node khác gửi đến
- Nếu term trả về lớn hơn term hiện tại: Candidate tự hiểu mình đã bị lỗi thời, nó tự chuyển về lại trạng thái Follower rồi đợi phản hồi từ Leader mới.
- Nếu đồng ý: Tăng số lượng bầu chọn lên 1.
Sau khi 2 giai đoạn kết thúc, các trường hợp có thể xảy ra là:
- Trường hợp 1: Nếu timeout nhưng không nhận đủ quá bán số bầu chọn: term hiện tại không nhận được đủ đồng thuận, Candidate lại tiếp tục tăng term lên 1 rồi bắt đầu lại quá trình bầu chọn Leader. Quá trình này có thể diễn ra vô hạn lần.
- Trường hợp 2: Nếu đạt được quá bán số bầu chọn: chuyển từ trạng thái candiate sang Leader, gửi thông báo cho toàn mạng biết
mình đã thành Leader. Sau đó bắt đầu quá trình
Log replicationvà cho phép nhận request từ client.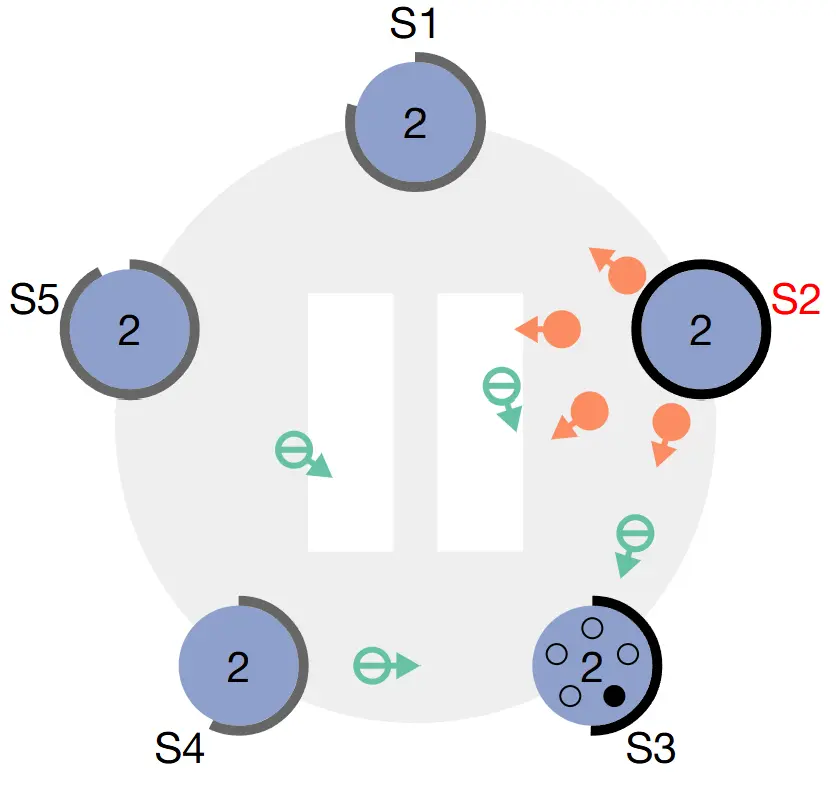
S2 đạt được quá bán bầu chọn và gửi thông báo cho toàn mạng, cùng lúc đó các node khác đã không bỏ phiếu cho S3 vì đã bỏ cho S2
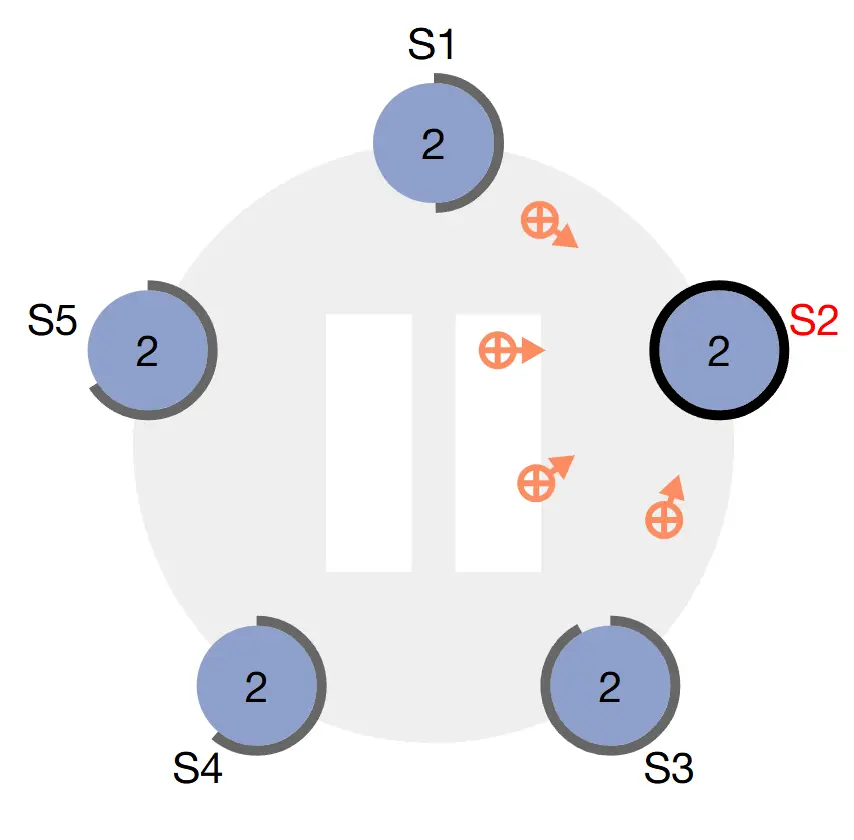
Log replication
Khi Leader đã được bầu chọn, nó bắt đầu nhận request từ client. Mỗi client request chứa một lệnh được thực thi bởi replicated State Machine.
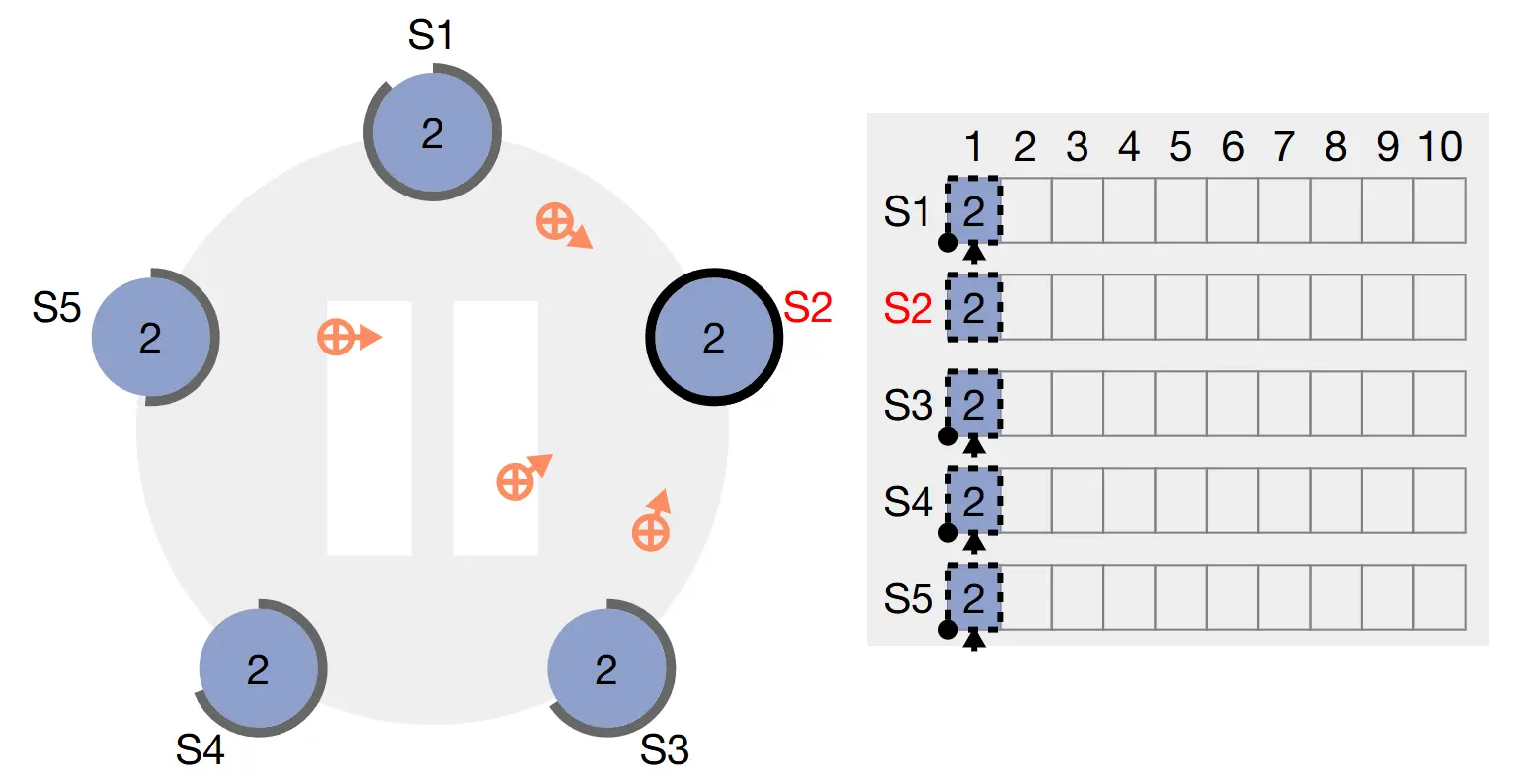
Leader thêm lệnh đó vào log của nó như là một entry mới, sau đó thông qua request AppendEntries để tiến hành replicate log qua các node.
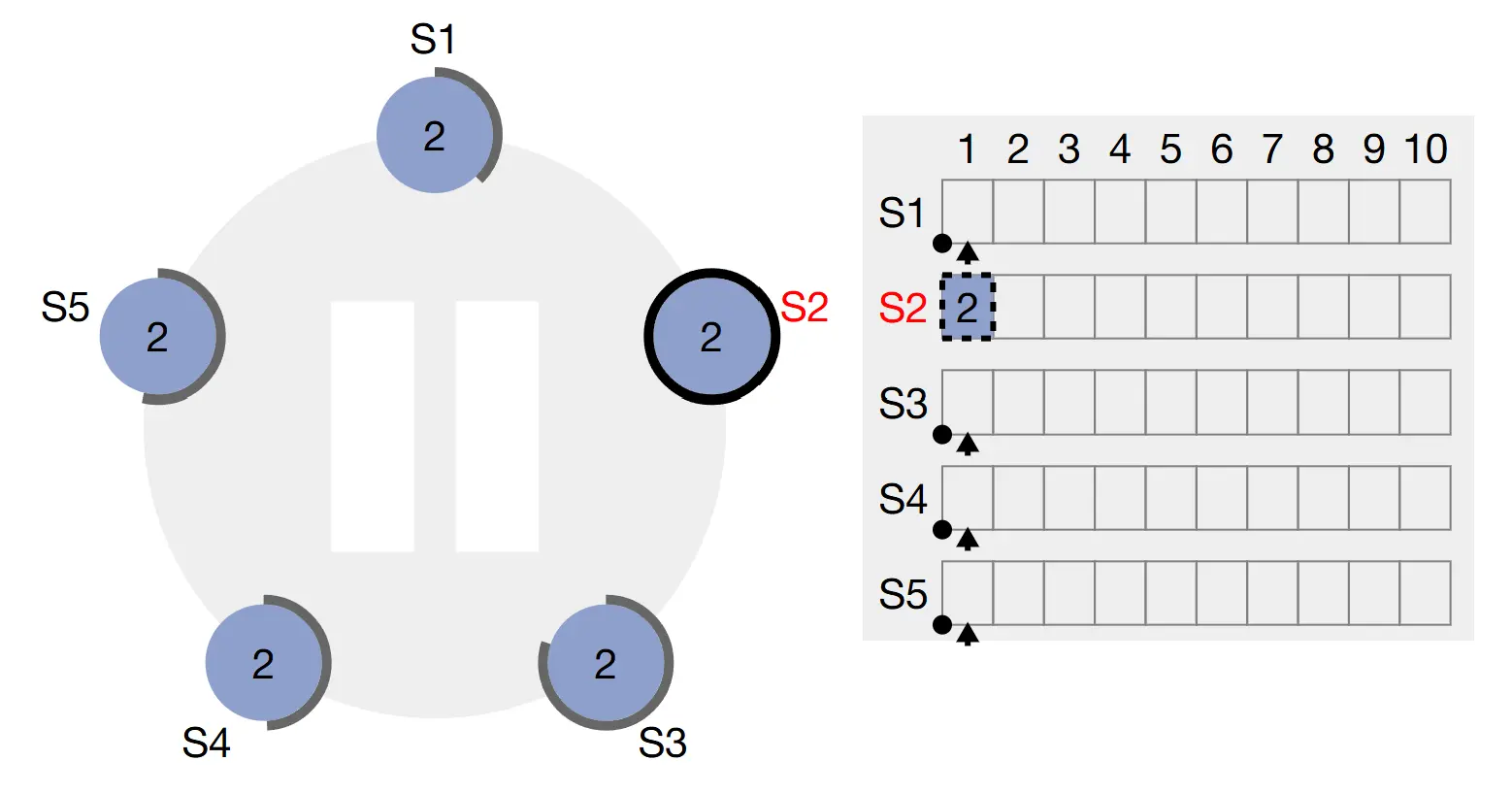
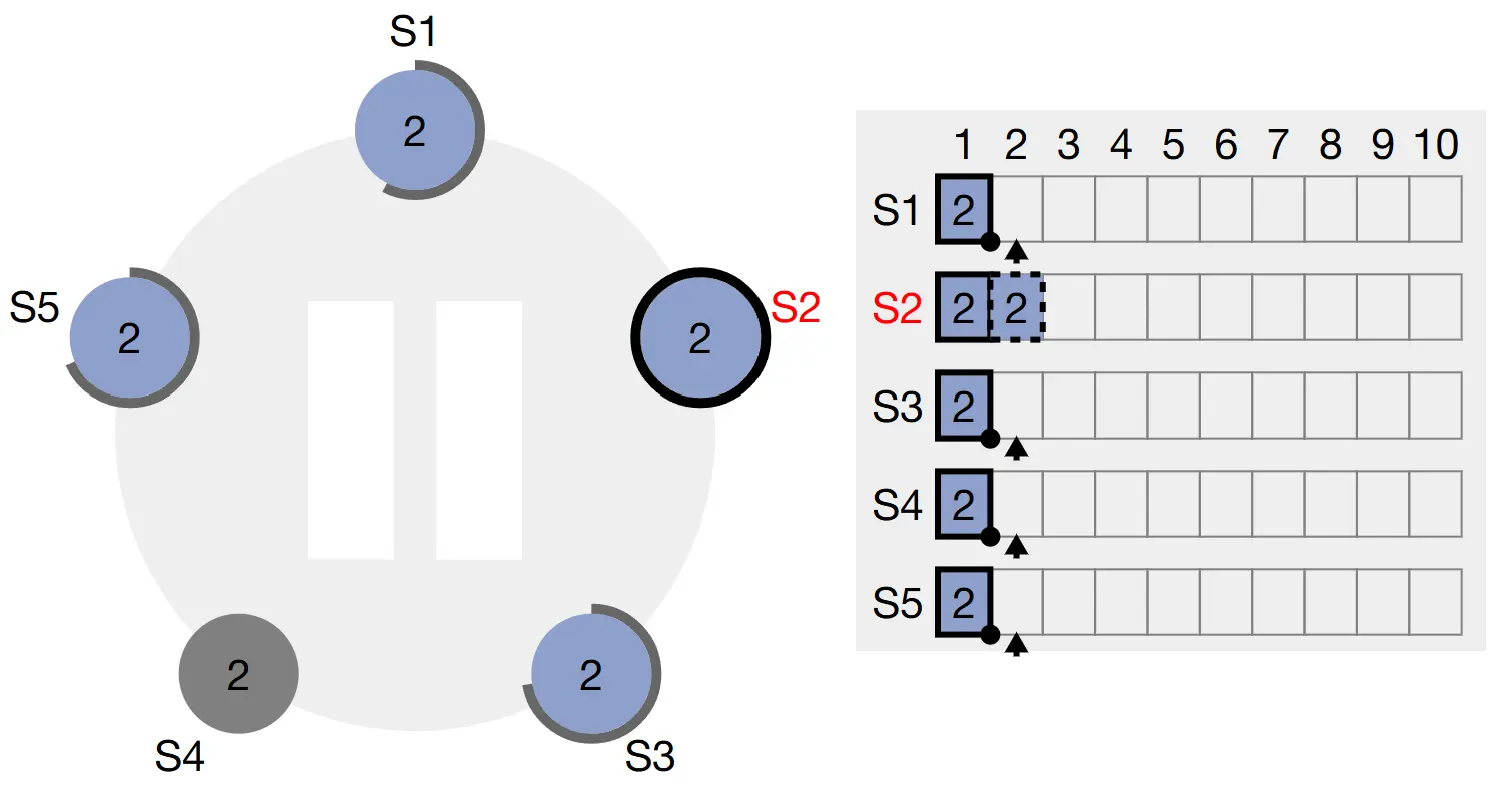
Khi entry đã được replicate, Leader apply entry đó vào state machine của nó và trả về kết quả thực thi về cho client.
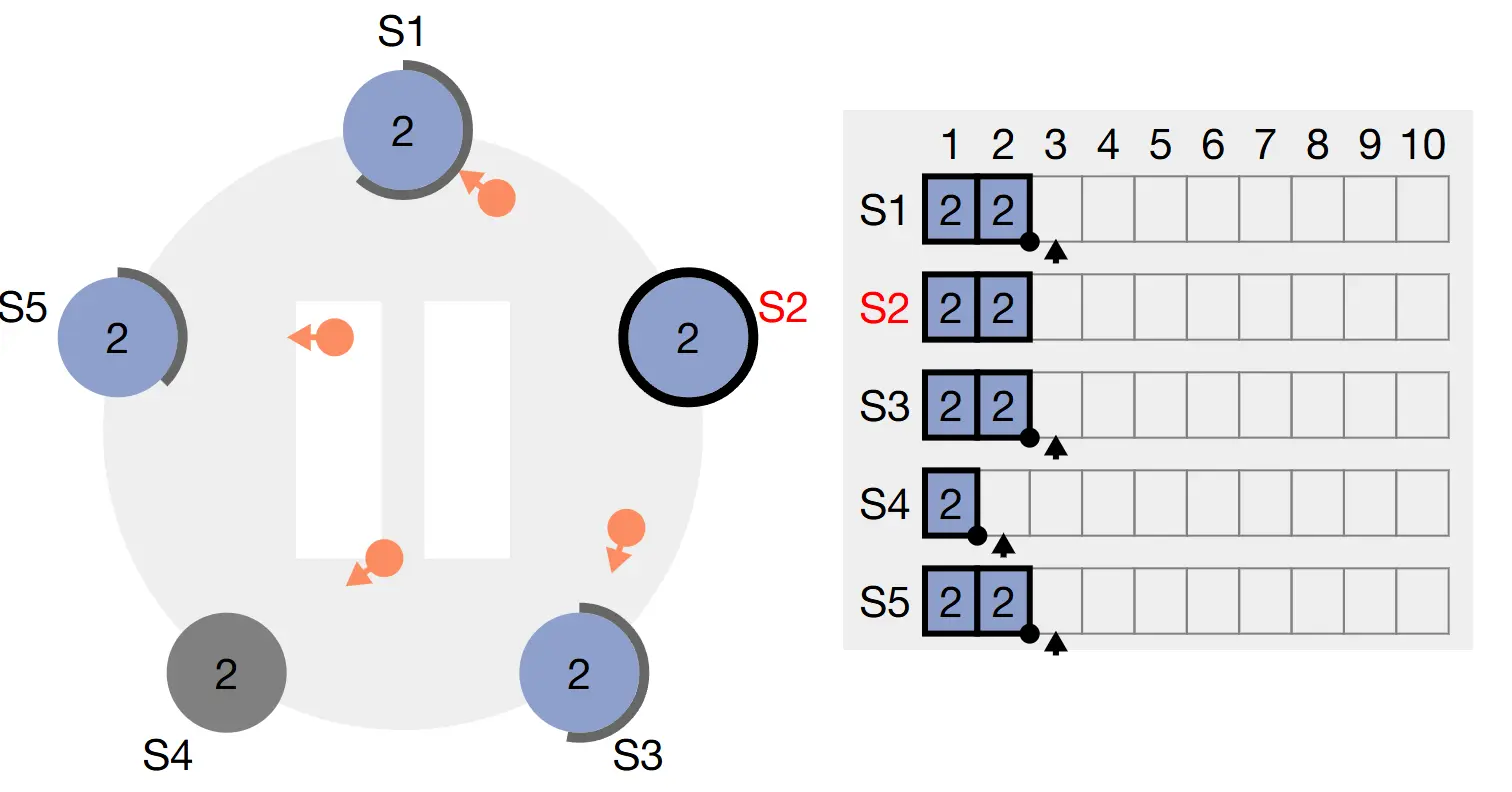
Trong quá trình replicate log, nếu Follower bị lỗi hoặc chạy chậm, hoặc gói tin mạng bị mất trong quá trình gửi tin thì Leader sẽ thực hiện lại request AppendEntries cho đến khi tất cả Follower lưu trữ được tất cả các log entry. Điều này có thể dẫn đến request AppendEntries được thực hiện vô hạn lần.
Tổng kết
Trên đây là trình bày cơ bản về bài toán đồng thuận và thuật toán Raft. Bài viết chỉ cung cấp cho các bạn hiểu được khái niệm và cách hoạt động của Raft, các vấn đề phát sinh khác như một số trường hợp đặc biệt khi thực thi; tương tác giữa client và Raft server bạn vui lòng tham khảo thêm ở paper chính của Raft hoặc các bài viết, paper khác.
Hi vọng bài viết mình trình bày đã giúp bạn có cái nhìn tổng quan về bài toán đồng thuận cũng như thuật toán Raft, nếu có thắc mắc hay đóng góp nội dung chỉnh sửa, vui lòng liên hệ mình để có thể trao đổi và cập nhật. Mình rất welcome các bạn ^^.