- Published at
Làm tí Redis - P2 - Dictionary

Hashmap của Redis
Table of Contents
Preface
Tài liệu được tham khảo từ source code của Redis v8. Các bạn có thể đọc tại đây: Redis repository
Thích đọc code Go hơn? Có luôn. Mình có 1 bản minimal về các data structure tại đây: Gedis repository
Dict, nghe như một cái keyword ở bên Python. Mà đúng như chức năng bên Python, ở Redis nó là một cái Hashmap siêu to dùng để lưu data.
C không có map như C++ (std::map), vì vậy Redis tự triển khai một cấu trúc dữ liệu gọi là dict nhằm tối ưu khả năng đọc ghi
cũng như optimize data. Dict được dùng để lưu cặp key-value và được sử dụng khắp Redis. Không chỉ để lưu hash data, mà còn
phục vụ biến đổi từ các cấu trúc dữ liệu khác như: Ziplist, Skiplist (2 khứa này nếu có thời gian sẽ viết sau, hihi).
Dict là một cấu trúc dữ liệu cần thiết để giải quyết vấn đề tìm kiếm. Thông thường thì cách giải quyết vấn đề tìm kiếm
thường chia làm 2 phần chính là balanced trees và hash tables. Mà thông thường chúng ta dùng sẽ là hash table hơn vì chúng
ta cũng k cần duy trì thứ tự của dữ liệu, nó lại nhanh nữa - O(1). Tuy nhiên thì cái nào cũng có cái khổ của nó, sử dụng hash table thì vấn đề cốt
lõi là làm sao kiểm soát được hash collision probability.
Do đó, Redis chọn hash table là giải thuật chính cho việc xây dựng dict. Cũng như bao thằng khác, hash table của Redis có:
- Các hash function để tính toán vị trí của value từ key.
- Dùng chaining để giải quyết hash collision.
- Tự động expand memory khi đạt tới ngưỡng cấp phát.
Tuy nhiên, có một cái khá là độc đáo của phiên bản dict này là rehashing. Đây là một kĩ thuật cho phép việc expand và đọc ghi không gây block
trong một thời gian dài, cũng như timeout các client, cũng là thứ khó nhất khi triển khai dict. Chi tiết như nào thì tí sẽ biết.
Data Structure
Dict Entry
Dict entry là đơn vị nhỏ nhất của một cấu trúc dữ liệu, nó chứa 3 thành phần: key, value và next - con trỏ trỏ đến phần tử tiếp theo
struct dictEntry {
struct dictEntry *next; /* Must be first */
void *key; /* Must be second */
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
};
Ngoài ra, cũng có một kiểu dữ liệu khác cho việc chỉ lưu key (phục vụ SET của Redis) như sau:
typedef struct dictEntryNoValue {
dictEntry *next; /* Must be first */
void *key; /* Must be second */
} dictEntryNoValue;
Tại sao lại cần tồn tại 2 cái riêng biệt? Define thêm phần value ở trong struct sẽ gây ra sự lãng phí tài nguyên không cần thiết.
Như ở dictEntry, một union type chiếm thêm 8 bytes. Giả sử ta cần lưu hàng tỉ key nhưng không cần value.
Ta phí hàng GB mà chẳng để làm gì, hơ hơ.
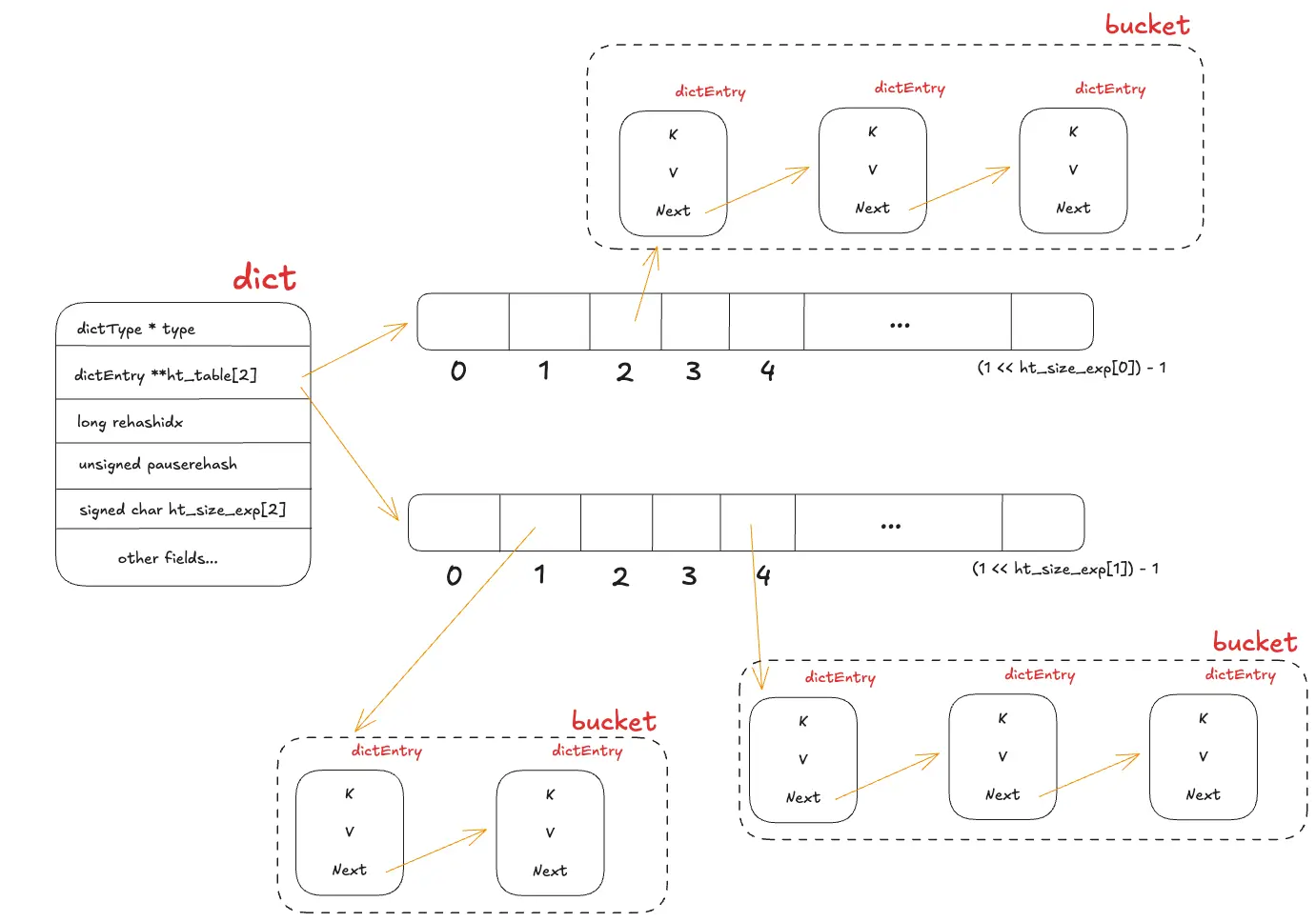
Dict
Cấu trúc của dict được mô tả như sau:
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Note: pauserehash is a full unsigned so iterator increments
* don't perform RMW on the same storage unit as other bitfields. */
unsigned pauserehash; /* If >0 rehashing is paused */
/* Keep small vars at end for optimal (minimal) struct padding */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
signed pauseAutoResize: 15; /* If >0 automatic resizing is disallowed (<0 indicates coding error) */
unsigned useStoredKeyApi: 1; /* See comment of storedHashFunction above */
void *metadata[];
};
Những field đáng chú ý:
**ht_table[2]: phục vụ việc lưu trữ dữ liệu, việc tồn tại 2 thay vì 1 tí sẽ được giải thích.ht_used[2]: track số lượng key đã lưu ở từng hashtable, phục vụ các config về fill rate và stats.rehashidx: biến để kiểm tra trạng thái hiện tại của hash table, với rehashidx = -1 nghĩa là đang không trong trạng thái rehashing, nếu > -1 thì có.pauserehash: biến để ngăn chặn việc thực hiện rehash, giúp dict tránh việc đọc 2 lần cho 1 key.ht_size_exp[2]: Size của các hash table, tính theo cấp số mũ. (2^exp == 1<<exp)
Có một field đầu tiên với kiểu dữ liệu là dictType *, đây là con trỏ hàm cho phép dict thực hiện các thao tác khác nhau
với key và value. Gồm có:
hashFunction: thuật toán hash để tính toán giá trị hash từ key.keyDupvàvalDup: Thực hiện deep copy cho key và value nếu cần.keyCompare: dùng để so sánh giữa 2 key, cái này được dùng khi mà ta đang tìm một phần tử trong dict bằng key.keyDestructorvàvalDestructor: define destructor functions cho key và value.
Với mỗi phần tử của hash table, nếu hash key có cùng giá trị, nó tạo thành một chaining dạng linked-list, Redis gọi nó là bucket.
Ta có thể mô tả lại cấu trúc của dict như hình dưới đây:
Dict Creation
/* Create a new hash table */
dict *dictCreate(dictType *type)
{
size_t metasize = type->dictMetadataBytes ? type->dictMetadataBytes(NULL) : 0;
dict *d = zmalloc(sizeof(*d)+metasize);
if (metasize > 0) {
memset(dictMetadata(d), 0, metasize);
}
_dictInit(d,type);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type)
{
_dictReset(d, 0);
_dictReset(d, 1);
d->type = type;
d->rehashidx = -1;
d->pauserehash = 0;
d->pauseAutoResize = 0;
d->useStoredKeyApi = 0;
return DICT_OK;
}
/* Reset hash table parameters already initialized with _dictInit()*/
static void _dictReset(dict *d, int htidx)
{
d->ht_table[htidx] = NULL;
d->ht_size_exp[htidx] = -1;
d->ht_used[htidx] = 0;
}
dictCreate cấp phát vùng nhớ cho dict và khởi tạo các giá trị ban đầu cho từng biến.
Trong đó, ta thấy 2 hash table ht_table[0] và ht_table[1] khi khởi tạo ban đầu không có vùng nhớ nào được cấp phát,
cả hai đều được gán giá trị là NULL. Điều này nghĩa là vùng nhớ thực sự chỉ được cấp phát khi có dữ liệu đầu tiên được
thêm vào dict.
Rehashing mechanism
Problem
Trước khi đến với chi tiết triển khai của Find, Insert và Delete. Có một bài toán ta cần làm rõ để hiểu được các phần
sau sẽ diễn ra như nào. Nên nhớ, kiến trúc của Redis là Single-Thread cho command execution, nên nó chỉ có thể làm một việc một lúc.
Ta hãy xét trường hợp sau:
Giả sử client A đang ghi dữ liệu vào dict. Lúc này, dict đã đạt đến ngưỡng cấp phát, cần mở rộng vùng nhớ để có thể tiếp tục lưu trữ.
Trong lúc đang mở rộng, client B cũng tiến hành yêu cầu ghi dữ liệu vào dict. Cần làm rõ, yêu cầu của client B xếp sau
client A nên sẽ không có vấn đề gì về mặt ghi đồng thời, nhưng làm sao để mọi thứ diễn ra trơn tru nhất?
Nếu chỉ có 1 hash table, phép ghi của client B phải chờ rất lâu khi phép ghi của client A đang
thực hiện cấp phát bộ nhớ. Ta có thể thấy rõ việc block do phải expand memory khiến cho performance tụt thê thảm.
Trong suốt quá trình cấp phát, không ai được phép làm gì cả, dẫn đến hàng loạt client cùng ngồi chờ.
Vậy nếu có thêm 1 hash table nữa như Redis thì làm được gì? Mời bạn đến với incremental rehashing.
How it works
Redis sử dụng 2 hash table luân phiên:
ht_table[0]: Hash table đang chứa dữ liệu chính.ht_table[1]: Hash table phụ, mặc định ban đầu sẽ làNULL. Việc khởi tạo sẽ chỉ diễn ra khi cần thực hiện rehash.
Vậy, với toàn bộ các phép ghi khi dict vẫn còn đủ vùng nhớ, dữ liệu sẽ được ghi vào ht_table[0].
Quay lại vấn đề, với việc ghi dữ liệu nhưng cần mở rộng bộ nhớ như trường hợp của client A. Redis tiến hành khởi tạo ht_table[1]
với kích thước gấp đôi ht_table[0], đồng nghĩa với việc ht_size_exp[1] sẽ lớn hơn ht_size_exp[0] 1 đơn vị.
Trong quá trình mở rộng, đánh dấu rehashidx = 0 để dict biết rằng nó đang ở trạng thái rehashing. Biến này đóng vai trò như
là con trỏ, chỉ vào index của hash table ht_table[0] đang chờ được di chuyển dữ liệu.
Lúc này, khi client B thực hiện ghi dữ liệu. Nó đầu tiên kiểm tra liệu dict có đang nằm trong trạng thái rehashing hay
không. Nếu có, tiến hành ghi dữ liệu vào ht_table[1] thay vì ht_table[0] như ở trạng thái non-rehashing.
Vậy, luồng đọc lúc này không bị block bởi việc expand nữa. Tuy nhiên dữ liệu sẽ được lưu ở 2 hash table khác nhau.
Sharing mechanism
Vậy sau khi đã lưu được dữ liệu ở cả 2 hash table, làm sao để reset về chỉ còn 1 hash table lưu dữ liệu, tức ht_table[0].
Để phòng trừ sau này lại cần rehash thì mới có ht_table[1] trống trơn mà mang ra xài. Từ đây một vấn đề mới sinh ra,
làm sao để bê mớ dữ liệu trước khi rehash từ ht_table[0] sang nốt ht_table[1] sau khi nó đã expand xong?
Việc để một operation nào đó thực hiện việc di chuyển toàn bộ dữ liệu về lại hash table gốc là khá nặng. Điều
đầu tiên có thể nghĩ đến là trigger một cronjob thực hiện dọn dẹp sau khi expand xong. Tuy nhiên, nếu làm vậy, ta lại quay về bài
toán ban đầu khi mà việc này lại gây ra block toàn bộ các client khác.
Redis có một cơ chế để giải quyết vấn đề này bằng cách:
- Với mỗi operation được client gọi đến, kiểm tra xem dict hiện tại có đang nằm trong trạng thái rehashing hay không?
- Nếu có, operation đó đóng vai trò như một công nhân phải phụ Redis thực hiện việc di chuyển 1 bucket từ
ht_table[1]sanght_table[0]tại vị trírehashidx. - Sau khi chuyển xong bucket đó, tăng giá trị của
rehashidxlên 1 (rehashidx++).
Nghe như kiểu muốn có ăn thì phải làm việc ấy =))) Với cơ chế này, latency của việc phải bê toàn bộ data được chia đều ra toàn bộ các operation, điều này chỉ gây ra việc tăng latency một chút ở mỗi operation chứ không gây ra block toàn bộ như cách cũ.
Sau khi toàn bộ bucket trong ht_table[0] đã được chuyển hết sang ht_table[1]. Tiến hành swap table như sau:
- Redis tiến hành giải phóng vùng nhớ của
ht_table[0]do lúc này đã trống rỗng. - Thực hiện
pointer swap: gánht_table[0] = ht_table[1]. Tức là hash table phụ lúc này thành chính. - Reset
ht_table[1] = NULLđể chuẩn bị cho lần mở rộng tiếp theo.
Double read and pauseRehash
Vấn đề mới được sinh ra khi thực hiện cơ chế chia sẻ công việc. Trước tiên, ta cần tìm hiểu về dictIterator - cấu trúc dữ liệu
giúp ta có thể duyệt qua dict.
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
unsigned long long fingerprint;
} dictIterator;
dictIterator giúp ta có thể duyệt qua toàn bộ dict khi cần thực hiện các câu lệnh như: KEYS hay SCAN
Xét trường hợp sau:
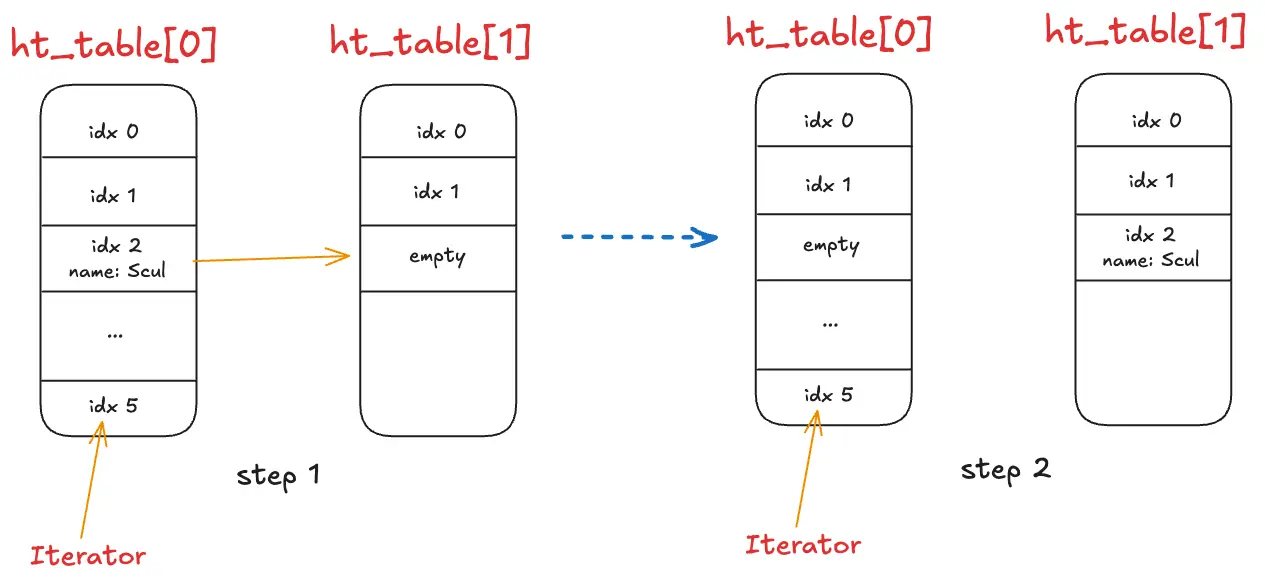
Khi duyệt qua toàn bộ các phần tử, Redis sẽ duyệt tuần tự từ ht_table[0] đến ht_table[1]. Ở ví dụ trên, tại step 1 ta
thấy iterator lúc này đã duyệt đến hết ht_table[0]. Tuy nhiên, trong quá trình duyệt, một operation khác thực thi rehash
khiến cho bucket tại index = 2 bị di chuyển sang ht_table[1]. Lúc này đến với step 2, iterator vẫn nằm im tại chỗ trong
khi đã có biến đổi xảy ra tại cả 2 hash table, đồng nghĩa với việc iterator sẽ đọc qua phần tử nằm tại bucket có index = 2
tại ht_table[1] một lần nữa, gây ra hiện tượng double read. Với các trường hợp chỉ cần scan kiếm dữ liệu thì ta có thể okay
với chuyện này, tuy nhiên với các command liên quan tới đếm thì sẽ gây ra sai số tại đây.
Redis giải quyết vấn đề này bằng pauseRehash counter. Field này sẽ tắt tạm thời việc xử lý incremental rehashing bằng cách:
- Tăng
pausrehashkhi khởi tạo mộtSafe Iterator(ví dụ: khi thực thi lệnhKEYShoặc khi Redis thực hiện lưu fileRDB/AOF). - Khi
pauserehash > 0, Redis sẽ tạm dừng hoàn toàn việcincremental rehashing. Điều này có nghĩa là các operation ghi/đọc khác của client dù có đi qua dict này cũng sẽ không kích hoạt việc di chuyển bucket từht_table[0]sanght_table[1]. - Việc này giữ cho cấu trúc của hash table ở trạng thái “tĩnh” trong suốt quá trình iterator hoạt động.
Iterator có thể yên tâm duyệt hết
ht_table[0]rồi sanght_table[1]mà không lo dữ liệu bị nhảy cóc hay dịch chuyển lung tung. - Sau khi iterator hoàn thành công việc và bị hủy (destroy), giá trị
pauserehashsẽ được giảm đi (pauserehash--). Khi biến này quay về 0, các operation tiếp theo sẽ lại tiếp tục công cuộc rehash còn dang dở.
Cơ chế này là một sự đánh đổi: Redis chấp nhận việc giải phóng bộ nhớ (do resize) bị chậm lại một chút để đổi lấy sự
chính xác tuyệt đối (Consistency) cho các tác vụ duyệt toàn bộ dữ liệu.
Find
Các bước có thể mô tả đơn giản như sau:
- Tính toán hash value cho key và vị trí cần tìm.
- Thực hiện rehash nếu trạng thái hiện tại đang là rehashing như mô tả ở trên.
- Duyệt qua từng hash table (chỉ duyệt
ht_table[1]nếu đang trong trạng thái rehashing). Với từng table, sử dụng hashed value để chỉ định đúng bucket cần duyệt. Trong quá trình tìm kiếm, sử dụngcmpFunccủa dict để so sánh, nếu có thì trả về, nếu không thì duyệt tiếp qua chain tiếp theo. - Cho đến khi duyệt qua hết các hash table, nếu không có phần tử nào, trả về
NULL.
Phần logic cốt lõi được thể hiện như sau:
/* Finds a given key. Like dictFindLink(), yet search bucket even if dict is empty.
*
* Returns dictEntryLink reference if found. Otherwise, return NULL.
*
* bucket - return pointer to bucket that the key was mapped. unless dict is empty.
*/
static dictEntryLink dictFindLinkInternal(dict *d, const void *key, dictEntryLink *bucket) {
dictCmpCache cmpCache = {0};
dictEntryLink link;
uint64_t idx;
int table;
if (bucket) {
*bucket = NULL;
} else {
/* If dict is empty and no need to find bucket, return NULL */
if (dictSize(d) == 0) return NULL;
}
const uint64_t hash = dictHashKey(d, key, d->useStoredKeyApi);
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
keyCmpFunc cmpFunc = dictGetCmpFunc(d);
/* Rehash the hash table if needed */
_dictRehashStepIfNeeded(d,idx);
int tables = (dictIsRehashing(d)) ? 2 : 1;
for (table = 0; table < tables; table++) {
if (table == 0 && (long)idx < d->rehashidx) continue;
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
/* Prefetch the bucket at the calculated index */
redis_prefetch_read(&d->ht_table[table][idx]);
link = &(d->ht_table[table][idx]);
if (bucket) *bucket = link;
while(link && *link) {
void *visitedKey = dictGetKey(*link);
/* Prefetch the next entry to improve cache efficiency */
redis_prefetch_read(dictGetNext(*link));
if (key == visitedKey || cmpFunc( &cmpCache, key, visitedKey))
return link;
link = dictGetNextLink(*link);
}
}
return NULL;
}
Insert
Khi thêm một phần tử, nó chia ra làm 2 phase:
- Phase đầu tiên là tìm xem phần tử đã có hay chưa, nếu đã có thì sẽ trả về existing index.
- Phase tiếp theo là sẽ dựa trên kết quả của phase đầu tiên để thêm phần tử mới vào.
Lưu ý ở đây, việc thực hiện rehash hay mở rộng vùng nhớ sẽ được quyết định bởi phase đầu tiên chứ không phải là phase sau. Phase sau chỉ dựa trên vị trí trả về và thêm thẳng vào.
/* Finds and returns the link within the dict where the provided key should
* be inserted using dictInsertKeyAtLink() if the key does not already exist in
* the dict. If the key exists in the dict, NULL is returned and the optional
* 'existing' entry pointer is populated, if provided. */
dictEntryLink dictFindLinkForInsert(dict *d, const void *key, dictEntry **existing) {
unsigned long idx, table;
dictCmpCache cmpCache = {0};
dictEntry *he;
uint64_t hash = dictHashKey(d, key, d->useStoredKeyApi);
if (existing) *existing = NULL;
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
/* Rehash the hash table if needed */
_dictRehashStepIfNeeded(d,idx);
/* Expand the hash table if needed */
_dictExpandIfNeeded(d);
keyCmpFunc cmpFunc = dictGetCmpFunc(d);
for (table = 0; table <= 1; table++) {
if (table == 0 && (long)idx < d->rehashidx) continue;
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
/* Search if this slot does not already contain the given key */
he = d->ht_table[table][idx];
while(he) {
void *he_key = dictGetKey(he);
if (key == he_key || cmpFunc(&cmpCache, key, he_key)) {
if (existing) *existing = he;
return NULL;
}
he = dictGetNext(he);
}
if (!dictIsRehashing(d)) break;
}
/* If we are in the process of rehashing the hash table, the bucket is
* always returned in the context of the second (new) hash table. */
dictEntry **bucket = &d->ht_table[dictIsRehashing(d) ? 1 : 0][idx];
return bucket;
}
/* Adds a key in the dict's hashtable at the link returned by a preceding
* call to dictFindLinkForInsert(). This is a low level function which allows
* splitting dictAddRaw in two parts. Normally, dictAddRaw or dictAdd should be
* used instead. It assumes that dictExpandIfNeeded() was called before. */
dictEntry *dictInsertKeyAtLink(dict *d, void *key, dictEntryLink link) {
dictEntryLink bucket = link; /* It's a bucket, but the API hides that. */
dictEntry *entry;
/* If rehashing is ongoing, we insert in table 1, otherwise in table 0.
* Assert that the provided bucket is the right table. */
int htidx = dictIsRehashing(d) ? 1 : 0;
assert(bucket >= &d->ht_table[htidx][0] &&
bucket <= &d->ht_table[htidx][DICTHT_SIZE_MASK(d->ht_size_exp[htidx])]);
if (d->type->no_value) {
if (!*bucket) {
/* We can store the key directly in the destination bucket without
* allocating dictEntry.
*/
if (d->type->keys_are_odd) {
entry = key;
assert(entryIsKey(entry));
/* The flag ENTRY_PTR_IS_ODD_KEY (=0x1) is already aligned with LSB bit */
} else {
entry = encodeMaskedPtr(key, ENTRY_PTR_IS_EVEN_KEY);
}
} else {
/* Allocate an entry without value. */
entry = createEntryNoValue(key, *bucket);
}
} else {
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
entry = zmalloc(sizeof(*entry));
assert(entryIsNormal(entry)); /* Check alignment of allocation */
entry->key = key;
entry->next = *bucket;
}
*bucket = entry;
d->ht_used[htidx]++;
return entry;
}
Delete
Tương tự như 2 operation ở trên, delete cũng thực hiện:
- Tìm phần tử cần xoá, đồng thời cũng thực hiện rehash nếu có.
- Xoá phần tử đó đi
- Shrink nếu size đang overfit.
Có một điểm khác ở đây là cơ chế shrink. Nó sẽ kiểm tra ht_table[0] hiện tại có đang thực sự cần cấp phát một bộ nhớ
lớn đến vậy không, nếu nhỏ hơn HASHTABLE_MIN_FILL. Nó sẽ được resize lại để đảm bảo không phí phạm vùng nhớ. Giá trị
mặc định của HASHTABLE_MIN_FILL là 8, tức 100/8 = 12.5%.
/* Search and remove an element. This is a helper function for
* dictDelete() and dictUnlink(), please check the top comment
* of those functions. */
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
dictCmpCache cmpCache = {0};
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
/* dict is empty */
if (dictSize(d) == 0) return NULL;
h = dictHashKey(d, key, d->useStoredKeyApi);
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
/* Rehash the hash table if needed */
_dictRehashStepIfNeeded(d,idx);
keyCmpFunc cmpFunc = dictGetCmpFunc(d);
for (table = 0; table <= 1; table++) {
if (table == 0 && (long)idx < d->rehashidx) continue;
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
prevHe = NULL;
while(he) {
void *he_key = dictGetKey(he);
if (key == he_key || cmpFunc(&cmpCache, key, he_key)) {
/* Unlink the element from the list */
if (prevHe)
dictSetNext(prevHe, dictGetNext(he));
else
d->ht_table[table][idx] = dictGetNext(he);
if (!nofree) {
dictFreeUnlinkedEntry(d, he);
}
d->ht_used[table]--;
_dictShrinkIfNeeded(d);
return he;
}
prevHe = he;
he = dictGetNext(he);
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
/* Returning DICT_OK indicates a successful shrinking or the dictionary is undergoing rehashing,
* and there is nothing else we need to do about this dictionary currently. While DICT_ERR indicates
* that shrinking has not been triggered (may be try expanding?)*/
int dictShrinkIfNeeded(dict *d) {
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the size of hash table is DICT_HT_INITIAL_SIZE, don't shrink it. */
if (DICTHT_SIZE(d->ht_size_exp[0]) <= DICT_HT_INITIAL_SIZE) return DICT_OK;
/* If we reached below 1:8 elements/buckets ratio, and we are allowed to resize
* the hash table (global setting) or we should avoid it but the ratio is below 1:32,
* we'll trigger a resize of the hash table. */
if ((dict_can_resize == DICT_RESIZE_ENABLE &&
d->ht_used[0] * HASHTABLE_MIN_FILL <= DICTHT_SIZE(d->ht_size_exp[0])) ||
(dict_can_resize != DICT_RESIZE_FORBID &&
d->ht_used[0] * HASHTABLE_MIN_FILL * dict_force_resize_ratio <= DICTHT_SIZE(d->ht_size_exp[0])))
{
if (dictTypeResizeAllowed(d, d->ht_used[0]))
dictShrink(d, d->ht_used[0]);
return DICT_OK;
}
return DICT_ERR;
}