- Published at
Build một cái K-V Database đơn giản như thế nào? (P2 - Storage and cache management)

Cách Bolt quản lý disk space bằng freelist và tận dụng mmap + OS page cache thay buffer pool truyền thống
Table of Contents
Disk space manager
Không như các DB lớn khác có khả năng shrinking (Postgres hay SQLite có VACUMM, MySQL có OPTIMIZE TABLE). Bolt DB sau khi yêu cầu disk space từ OS thì dù cho có xoá dữ liệu đi nó cũng không trả lại disk space thừa cho OS. Lý do cho điều này là ý tưởng của LMDB là giảm thiểu system call và disk operator. Trade off cho việc này là bộ nhớ. Do đó, Bolt sử dụng Free page để quản lý các page trống. Vì vậy việc tổ chức Heap File để quản lý disk space chính là freelist đã đề cập ở bài trước.
Freelist chịu trách nhiệm quản lý việc cấp phát và thu hồi các page trống. Khi các read-write transaction yêu cầu disk space, freelist luôn cố gắng tìm một disk space liên tiếp về mặt vật lý đáp ứng kích thước cần thiết trước. Nếu tìm thấy thì cấp phát trực tiếp; nếu không thì yêu cầu disk space mới từ hệ điều hành. Ta sẽ quay lại tiếp tục tìm hiểu nó ở DB Layer để xem việc cấp phát diễn ra cụ thể như thế nào.
Cấu trúc
Cấu trúc của freelist như sau:
// freelist represents a list of all pages that are available for allocation.
// It also tracks pages that have been freed but are still in use by open transactions.
type freelist struct {
ids []pgid // all free and available free page ids.
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
Freelist lưu các page id trống vào ids và được sắp xếp tuần tự, ví dụ như:

Vì sao cần pending page và chiến lược cấp phát của freelist:
Khi gặp việc xóa dữ liệu, các read-write transaction sẽ giải phóng disk space thừa trở lại freelist. Lúc này, freelist sẽ không ngay lập tức cấp phát lại mà sẽ đánh dấu những page được giải phóng này là trạng thái pending (pending page), cho đến khi không có transaction đọc nào trong hệ thống phụ thuộc vào dữ liệu cũ trong những page này, thì mới chính thức thu hồi và tái cấp phát. Kịch bản ví dụ như sau:
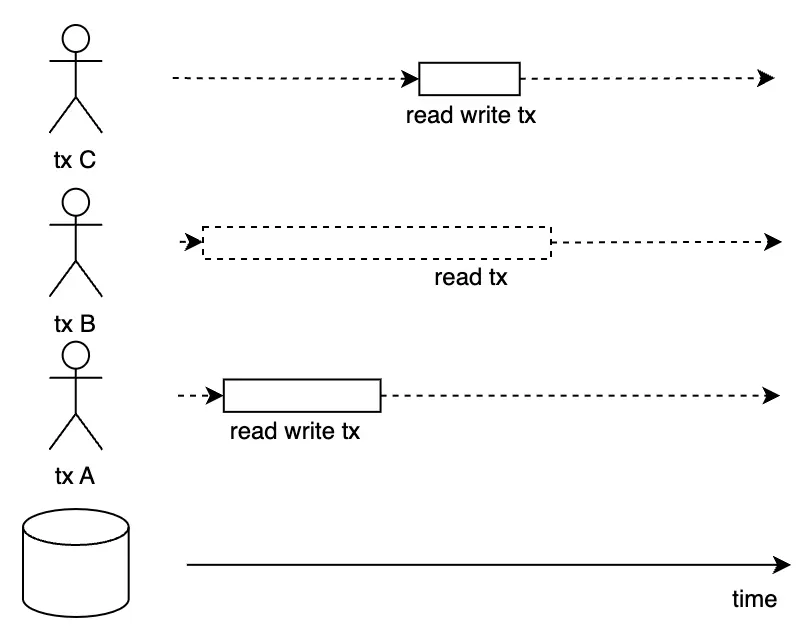
-
Read-only ransaction B đang chạy. Lúc này, read-write transaction A xóa một phần dữ liệu khỏi cơ sở dữ liệu và giải phóng disk space tương ứng trở lại freelist.
-
Nếu lúc này freelist ngay lập tức cấp phát những page vừa được giải phóng cho read-write transaction C tiếp theo, transaction sau có thể thay đổi chúng và persist xuống đĩa. Trong quá trình này, transaction read-only B vẫn đang đọc dữ liệu và có thể đọc các phiên bản khác nhau của cùng một dữ liệu → Vi phạm
isolation, có thể gây ra hiện tượngNon-repeatable readhoặcPhantom read. -
Vì vậy, Bolt triển khai thực tế bằng cách: khi transaction A giải phóng disk space, freelist chỉ đánh dấu nó là trạng thái
pending, chờ các transaction như B vẫn phụ thuộc vào những page này hoàn thành thực thi trước khi thu hồi và tái sử dụng, từ đó tránh data inconsistency và đảm bảo transaction isolation. Chiến lược giải phóng này đặc biệt quan trọng trong việc thực hiện kiểm soát đồng thờiđa phiên bản cơ sở dữ liệu (Multi-version concurrency control). Chúng ta sẽ tiếp tục thảo luận chủ đề này trong phầnTransaction.
Các thao tác chính của Freelist:
Ta có một vài thao tác chính cần quan tâm như sau:
allocate: tìm kiếm vùng free page liên tiếp thoả mãn n page, trả về page id đầu tiên của vùng.rollback: phục vụ transaction rollback: chuyển từ pending page về in-use page. (Chỉ remove tx khỏi cache và pending)reindex: rebuild free cache (cache attr của freelist) dựa trên free id list và pending list của freelist hiện tại. Được gọi cuối cùng sau khi khởi tạo DB hoặc reload.write: phục vụ transaction commit chuyển đổi page thành freelist page và lưu cứng dưới disk. Nó xử lý cả các overflow page liên quan.reload: phục vụ transaction rollback: Thống nhất disk state với runtime state hiện tại.
NOTE: Khi một transaction thực hiện rollback, nó thực hiện đồng thời 2 lệnh rollback() và reload vì nếu chỉ có mỗi rollback() thì in-memory state lúc này có thể chưa chính xác với state thực sự.
Lấy ví dụ sau:
-
Initial state:
- Disk freelist: [5, 7, 9]
- f.ids: [5] (available)
- f.pending: tx1: [7], tx2: [9]
-
tx1 thực hiện rollback():
- Sau khi thực hiện freelist.rollback(tx1): f.pending = tx2: [9]
- Nhưng f.ids vẫn = [5]
- Vấn đề: page 7 bây giờ phải available mới đúng!
-
tx1 thực hiện reload():
- Reads disk: [5, 7, 9]
- Lọc ra pending tx2: [9]
- Kết quả: f.ids = [5, 7] ✓ Correct!
Memory Management (Buffer Pool)
Khi nhắc đến buffer pool, nhiều người thường nghĩ ngay đến những implementation phức tạp như trong MySQL hay PostgreSQL. Nhưng LMDB/Bolt lại có cách tiếp cận hoàn toàn khác biệt - một cách tiếp cận mà mình cho là “thông minh hơn”.
Các database engines truyền thống thường tự implement buffer pool với kiến trúc như sau:
Application Layer:
[Fixed-size Pool] → [Page Cache] → [LRU Eviction] → [Explicit Management]
Các database engines như MySQL, PostgreSQL ra đời khi operating systems chưa mature về memory management. Lúc đó, OS page cache còn “ngố”, virtual memory chưa được optimize tốt, nên database phải tự lo mọi thứ. Điều này vừa đem lại mặt lợi nhưng cũng vừa khiến cho hệ thống trở nên phức tạp hơn vì ta phải tự làm những công việc như: Quản lý dirty page, Write-back policy, Cache warming, Eviction Algorithm, …
Với LMDB/Bolt, lúc ra đời của nó thì OS page cache lúc này đã được tối ưu đủ tốt để giao nhiệm vụ cho nó thay vì phải tự tay triển khai lại. Có một triết lý khá hay của LMDB nói rằng:
Don’t fight the OS, embrace it
Việc sử dụng OS page cache đem lại nhiều lợi ích cho LMDB/Bolt như:
- Zero-copy magic: Với mmap, data không cần được copy từ kernel space sang user space. Khi application đọc data:
Traditional approach: Disk → OS Page Cache → Buffer Pool → Application (2 copies) mmap approach: Disk → OS Page Cache → Application (0 copy) - Memory pressure handling: Tự động evict pages khi memory thiếu
- Demand paging: Chỉ load pages khi thực sự cần
Tuy nhiên, cái gì cũng có trade-off cả:
| Cons | Pros |
|---|---|
| Không thể force evict pages cụ thể | Code đơn giản, ít bugs |
| Không control được chính xác write-back timing | Performance thường tốt hơn (zero-copy + OS optimizations) |
| Phụ thuộc vào OS scheduler | Không cần tuning memory parameters |
| Automatic scaling theo available system memory |
Vậy, “Buffer Pool” của Bolt thực chất là: OS Page Cache + Virtual Memory System, được truy cập thông qua mmap syscall. Bolt không có Buffer Pool theo nghĩa truyền thống, nó tin tưởng OS để làm những việc OS làm tốt nhất.
Đây cũng là lý do tại sao các modern storage engines như RocksDB, LevelDB cũng đang trend về hướng “OS-friendly” hơn, thay vì cố gắng outsmart operating system.
Read Buffer Pool:
mmap là system call được cung cấp bởi hệ điều hành, nó ánh xạ trực tiếp dữ liệu từ một file hoặc thiết bị trong hệ thống vào một khối bộ nhớ ảo có kích thước cho trước. Khối bộ nhớ ảo này có thể lớn hơn hoặc nhỏ hơn kích thước không gian thực sự mà file hoặc thiết bị đó chiếm giữ. Sau khi ánh xạ hoàn thành, ứng dụng có thể giả định (mặc dù thực tế không phải) rằng tất cả dữ liệu từ đối tượng được ánh xạ đã được đọc vào bộ nhớ và có thể truy cập tùy ý dữ liệu trong khối bộ nhớ ảo này. Hệ điều hành chịu hoàn toàn trách nhiệm đọc và ghi dữ liệu có buffer phía sau.
Bolt sử dụng mmap để quản lý buffer đọc dữ liệu, để hệ điều hành quyết định khi nào đọc dữ liệu vào bộ nhớ và cách chọn dữ liệu để thay thế khi kích thước buffer không đủ. Bolt chỉ cần truy cập file cơ sở dữ liệu như truy cập mảng byte. Tất nhiên, việc sử dụng mmap cũng mất quyền kiểm soát việc đọc dữ liệu và không thể tối ưu hóa data prefetching và buffer replacement theo logic chạy của hệ thống cơ sở dữ liệu. Dù vậy, trong thực tế Bolt luôn chọn mmap file cơ sở dữ liệu vào một khối bộ nhớ ảo không nhỏ hơn kích thước của file cơ sở dữ liệu, do đó thực tế chỉ có demand paging, không có buffer replacement.
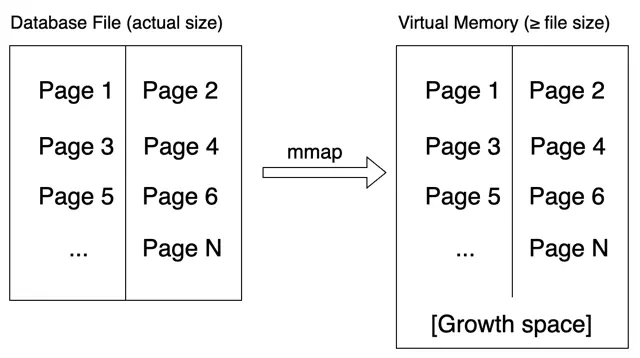
Lấy đơn giản ví dụ sau:
func mmap(db *DB, sz int) error {
// Map entire database file into virtual memory
b, err := syscall.Mmap(
int(db.file.Fd()), 0, sz,
syscall.PROT_READ, syscall.MAP_SHARED
)
if err != nil {
return err
}
// Treat mapped memory as a giant byte array
db.data = (*[maxMapSize]byte)(unsafe.Pointer(&b[0]))
return nil
}
Sau khi thực thi hàm mmap, instance Bolt nhận được một địa chỉ bộ nhớ. Trong góc nhìn của instance BoltDB, một không gian bộ nhớ liên tiếp bắt đầu từ địa chỉ này ánh xạ tới file cơ sở dữ liệu, và nó có thể truy cập ngẫu nhiên dữ liệu trong đó:
func (db *DB) page(id pgid) *page {
pos := id * pgid(db.pageSize)
return (*page)(unsafe.Pointer(&db.data[pos]))
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// Direct memory access - no buffer pool lookup!
}
Write Buffer Pool
Đối với writes, Bolt từ bỏ write buffering phức tạp để ủng hộ chiến lược đơn giản nhưng hiệu quả: Khi các read-write transaction commit, tất cả dirty page sẽ được persist xuống đĩa. Trước khi persist, Bolt sắp xếp những page này theo thứ tự tăng dần của page id, sau đó ghi chúng xuống đĩa theo thứ tự. Vì tất cả page trong file cơ sở dữ liệu được sắp xếp theo thứ tự tăng dần của id và kề nhau, việc ghi ra như vậy là ghi tuần tự, rất thân thiện với thiết bị lưu trữ khối.
func (tx *Tx) write() error {
// Sắp xếp pages theo ID để ghi tuần tự
sort.Sort(tx.pages)
// Ghi pages tuần tự vào disk
for _, p := range tx.pages {
// Sequential I/O nhanh hơn random I/O rất nhiều
if err := tx.writeAt(p.id*pgid(tx.db.pageSize), p); err != nil {
return err
}
}
return nil
}
Kết
Vậy là xong, ta đã tìm hiểu được thêm phần quản lý bộ nhớ cũng như cách Bolt sử dụng OS mmap như nào. Nhưng đó mới chỉ là “raw materials”. Vấn đề thực sự là: khi application muốn lấy value từ một key, làm sao Bolt biết chính xác key đó nằm ở page nào thay vì scan toàn bộ database?
Đây chính là lúc ta cần một data structure thông minh để tổ chức và tìm kiếm key-value pairs hiệu quả - và đó chính là Data Structure ở phần tiếp theo.