- Published at
Build một cái K-V Database đơn giản như thế nào? (P3 - Data Structure)

Cấu trúc B+ Tree của Bolt, rebalance & spill khi commit, và dereference để tránh lỗi pointer.
Table of Contents
Tổng quan
Đối với cơ sở dữ liệu dạng disk-based, hiệu suất thường bị bottleneck ở disk I/O, do đó số lần thực hiện disk I/O thường được sử dụng để đo lường hiệu suất của các thao tác khác nhau trong loại cơ sở dữ liệu này, và giảm disk I/O trở thành mục tiêu thiết kế quan trọng. B+ Tree được sinh ra để tối ưu hóa disk I/O trong quá trình truy vấn dữ liệu. Nó có thể kết hợp tốt truy vấn dữ liệu với block storage, giảm số lần I/O cần thiết cho mỗi lần đọc dữ liệu. Bolt sử dụng B+ Tree làm index và đặt tất cả dữ liệu K-V trong các leaf node.
Một page trên disk tương ứng với một node trên B+ Tree. Quá trình cơ sở dữ liệu tải page từ disk là quá trình deserialize nó thành node, và quá trình ghi dữ liệu vào disk là quá trình serialize node thành page. Các branch page và leaf page được giới thiệu trong phần trước tương ứng chính xác với branch node và leaf node trên B+ Tree. Có thể hiểu rằng mỗi phần dữ liệu chỉ có một field, do đó chỉ cần thiết lập index trên trường này. Bolt lưu trữ trực tiếp dữ liệu trên các leaf node của B+ Tree tương tự như primary index trong cơ sở dữ liệu quan hệ.
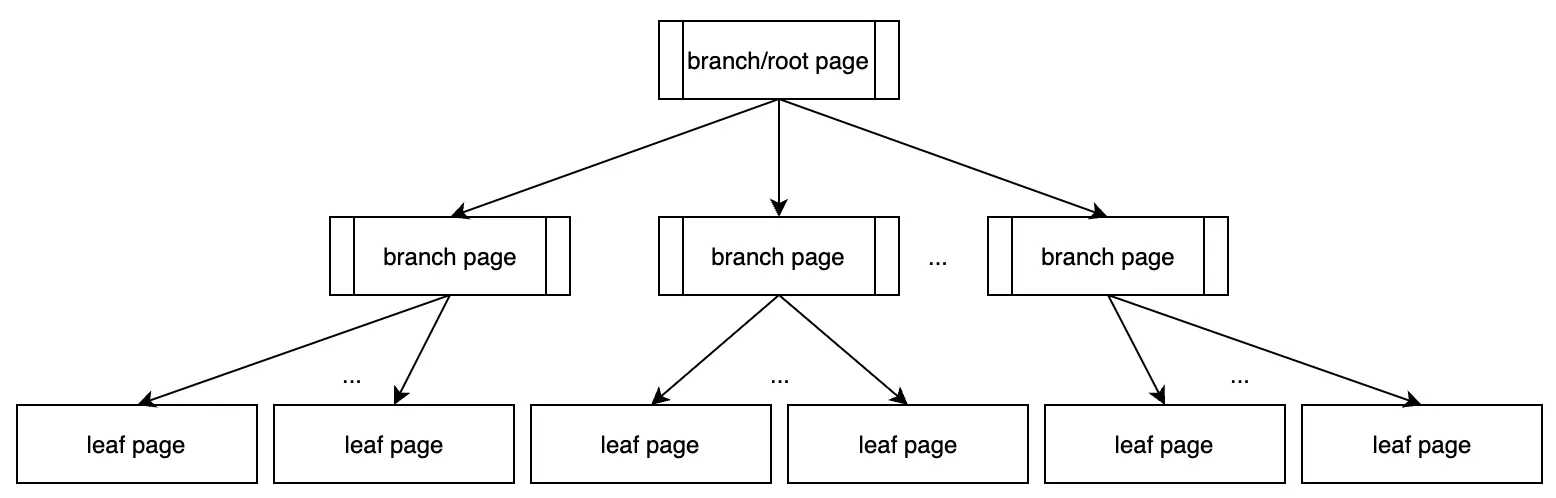
Cấu trúc
Cấu trúc của mỗi node trên B+ Tree bao gồm header, danh sách element header và danh sách dữ liệu theo thứ tự. Branch node chỉ lưu trữ key làm dữ liệu, trong khi leaf node lưu trữ các cặp K-V.
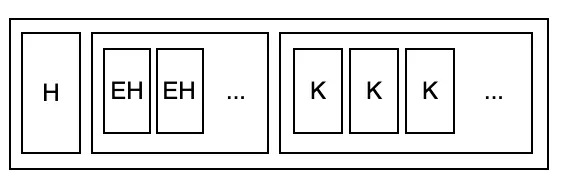
- Branch node được đơn giản hoá như sau:
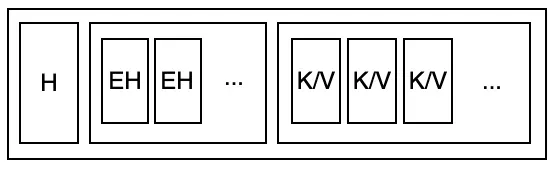
- Leaf node được đơn giản hoá như sau:
- Sử dụng branch node và leaf node được đơn giản hóa, có thể xây dựng một B+ Tree hợp lệ:
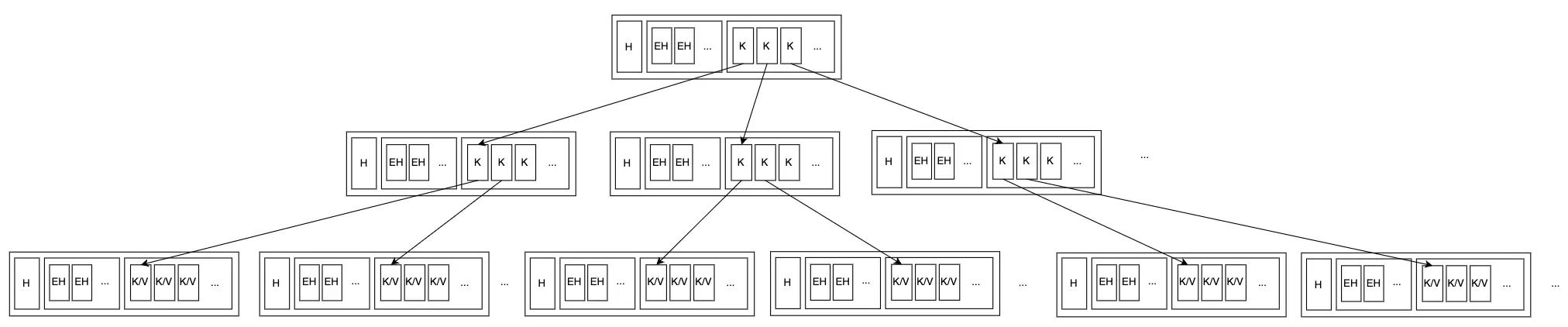
Các đặc tính của cây này về cơ bản tương tự như các khái niệm B+ Tree ta thường thấy, nhưng có một chút khác biệt:
- Toàn bộ B+ Tree là cây cân bằng hoàn hảo, nghĩa là mọi leaf node đều có cùng độ sâu.
- Ngoại trừ root node, các node khác cần có tỷ lệ fill lớn hơn FillPercent, mặc định là 50%. Bolt cũng có chặn dưới và chặn trên cho FillPercent lần lượt là 10% và 100%.
- Tất cả các cặp K-V được lưu trữ trong leaf node. Branch node chỉ lưu trữ key tối thiểu của mỗi child node (như được chỉ ra bởi mũi tên trong hình trên). Kích thước của key được xác định bởi thứ tự byte của key.
Cấu trúc cụ thể:
type node struct {
bucket *Bucket // Bucket chứa node hiện tại
isLeaf bool // Flag dùng cho việc check leaf node
unbalanced bool // Flag dùng cho việc check trạng thái cân bằng của cây
spilled bool // Flag dùng cho việc check trạng thái cây có bị tràn hay chưa
key []byte // Lưu trữ first key trong inodes để làm định danh với các parent node
pgid pgid
parent *node
children nodes
inodes inodes // Các node lưu trữ dữ liệu thực sự được ghi trong disk
}
type nodes []node
type inodes []inode
type inode struct {
flags uint32 // dùng để phân biệt inode của page nào, branch thì không dùng value.
pgid pgid // dùng cho branch inode, pgid ở đây là để trỏ đến child node
key []byte
value []byte
}
Thuật toán
Bolt không trực tiếp thay đổi cấu trúc cây khi cập nhật dữ liệu B+ Tree, mà chỉ cập nhật dữ liệu. Các node được hợp nhất và tách theo nhu cầu trước khi dữ liệu được ghi vào disk để khôi phục các bất biến của B+ Tree. Nói một cách nghiêm ngặt, B+ Tree trong Bolt là B+ Tree trên disk. Khi các thao tác cập nhật được thực hiện trong memory và chưa được ghi vào disk, nó có thể không tuân theo các đặc tính của B+ Tree.
Ta sẽ tìm hiểu các thao tác chính có tham gia thay đổi cấu trúc B+ Tree:
Chèn
Việc chèn dữ liệu có thể khiến dữ liệu trong node vượt quá kích thước của một page:
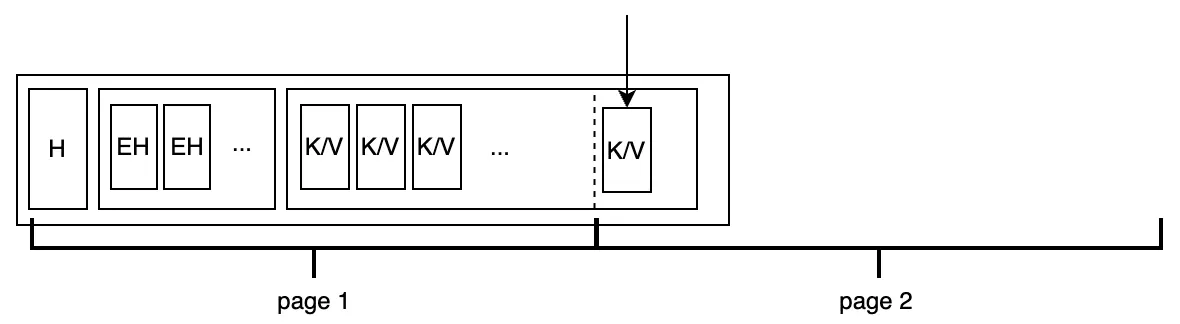
Chúng ta cũng cần xem xét trường hợp một cặp khóa-giá trị quá lớn:
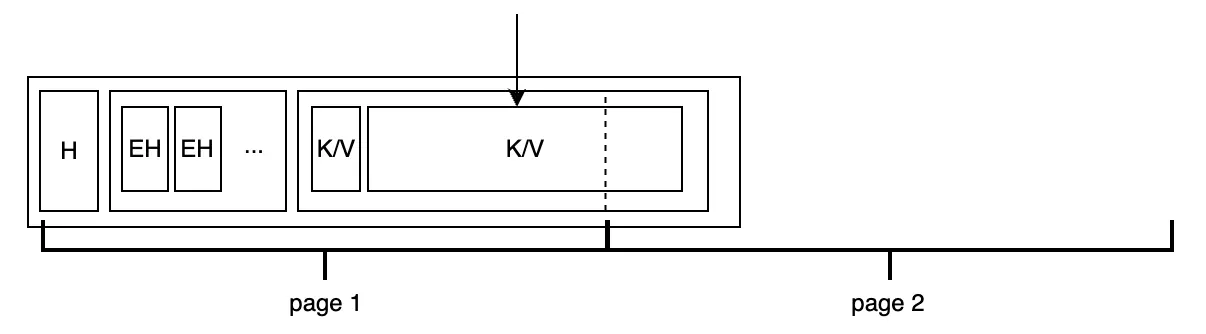
Bolt chỉ đơn giản để Put operator thực thi việc ghi mà sẽ không check việc tràn dữ liệu ngay lập tức. Điều này giúp cho việc batch processing hiệu quả hơn mà không gây cản trở. Nó chỉ cần tập trung split khi bắt đầu ghi xuống đĩa.
Xoá
Việc xóa dữ liệu có thể đưa node vào trạng thái không cân bằng, tức là sau khi các cặp khóa-giá trị được xóa, tổng khối lượng dữ liệu trong node nhỏ hơn tỷ lệ fill tối thiểu (FillPercent):
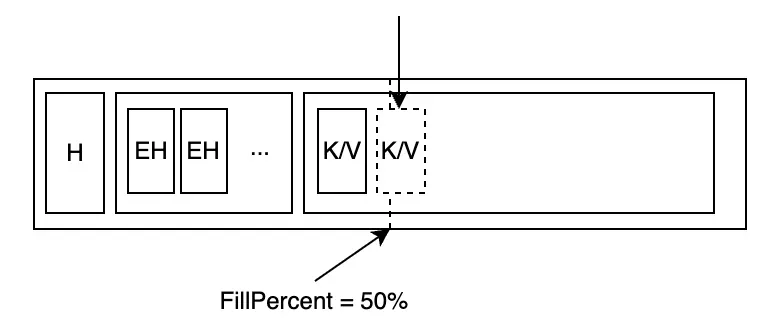
Khi thao tác xóa khiến tỷ lệ fill của node giảm xuống dưới yêu cầu, mặc dù nó sẽ không ngay lập tức hợp nhất với sibling node, nhưng node sẽ được đánh dấu là unbalanced trước khi kết thúc. Điều này là vì rebalance operator rất tốn kém về hiệu năng, đánh dấu unbalanced ngay lập tức như là 1 label cho các node khác biết rằng node này hiện tại đã đủ nhỏ và hãy tìm node khác (mình đoán vậy chứ thấy source cũng chưa implement cái kĩ thuật này mà chỉ đơn giản là đánh dấu rồi để đó =)) ), và việc hợp nhất sẽ xảy ra trước khi dữ liệu được ghi vào đĩa.
Rebalance
Mục đích của Rebalance là hợp nhất các node có tỷ lệ fill không đủ với sibling node.
Rebalance chỉ được gọi khi bắt đầu ghi dữ liệu xuống đĩa (khi một transaction thực hiện Commit).
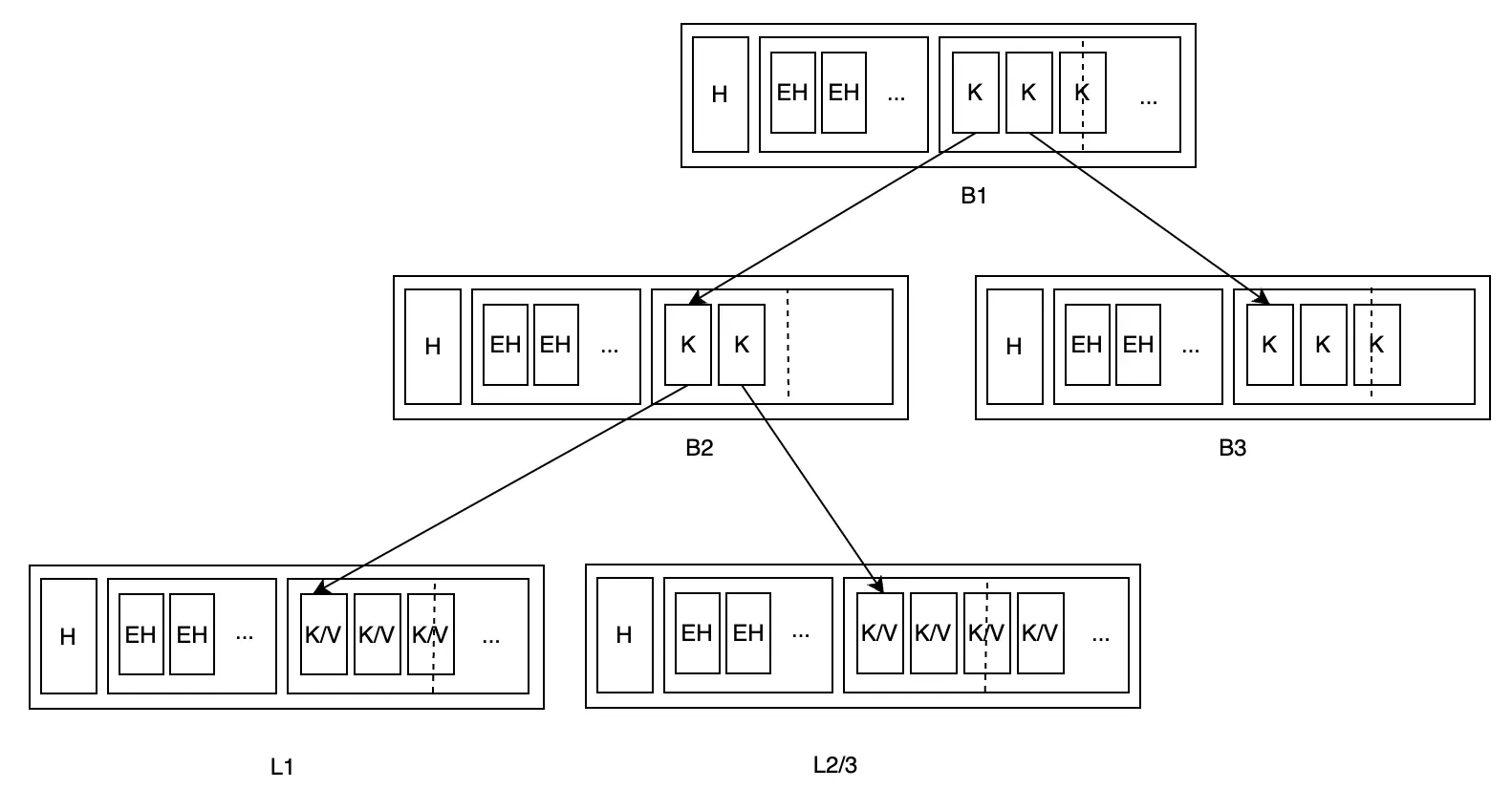
Tất cả leaf node đã trải qua thao tác xóa sẽ được đánh dấu là unbalanced, và consumer cho các dấu hiệu này là rebalance. Nó chịu trách nhiệm hợp nhất các node có tỷ lệ fill không đủ (dưới FillPercent) với sibling node tương ứng. Lấy hình dưới đây làm ví dụ (đường đứt nét trong hình biểu thị tỷ lệ fill):
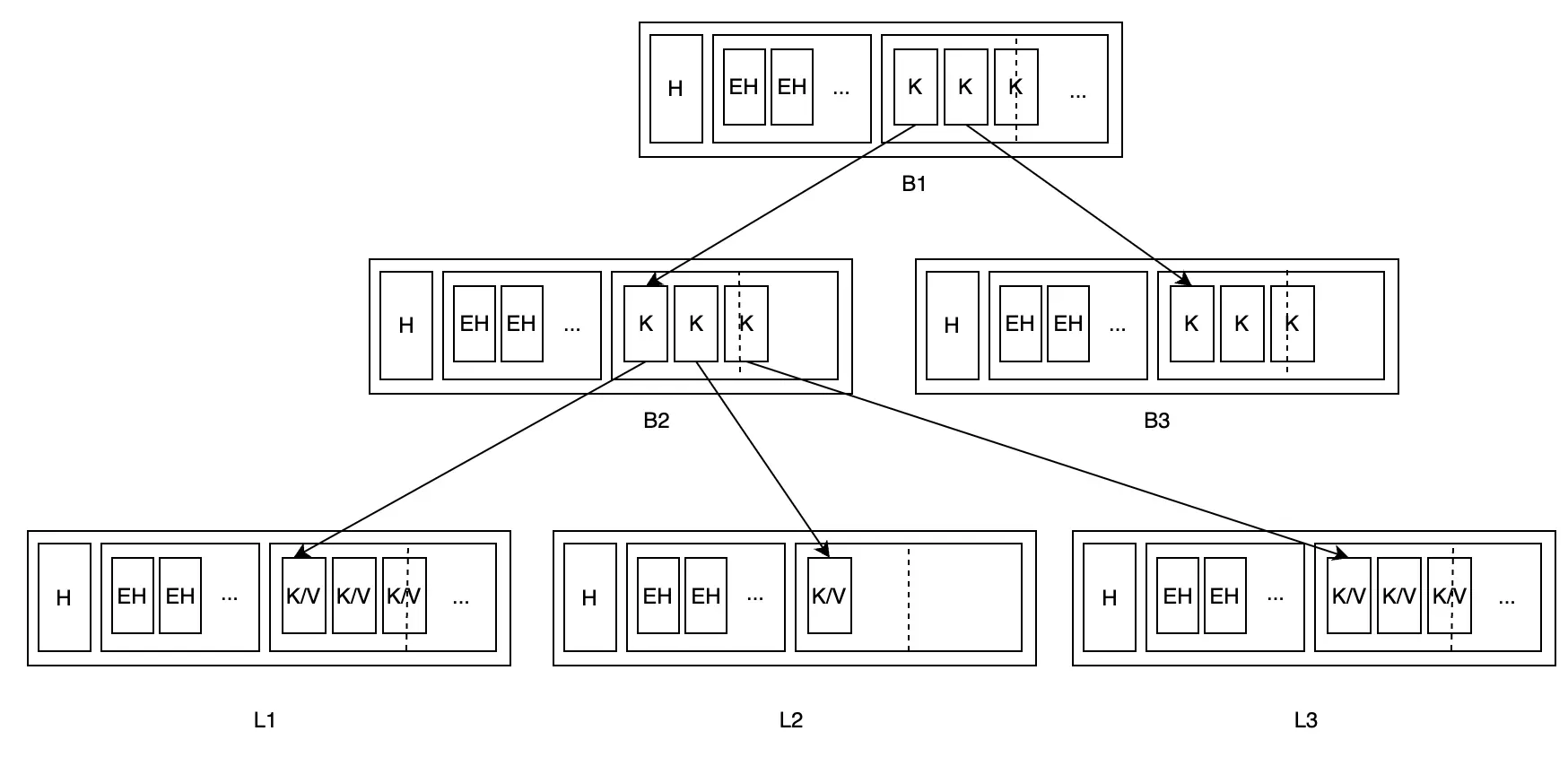
Khi tổng khối lượng dữ liệu của L2 không đủ, rebalance tìm sibling node L3 của nó, hợp nhất hai node và cập nhật parent node B2 của chúng:
Lúc này, tổng khối lượng dữ liệu của B2 nhỏ hơn FillPercent, nên rebalance cần đệ quy tiếp tục hợp nhất B2 với B3:
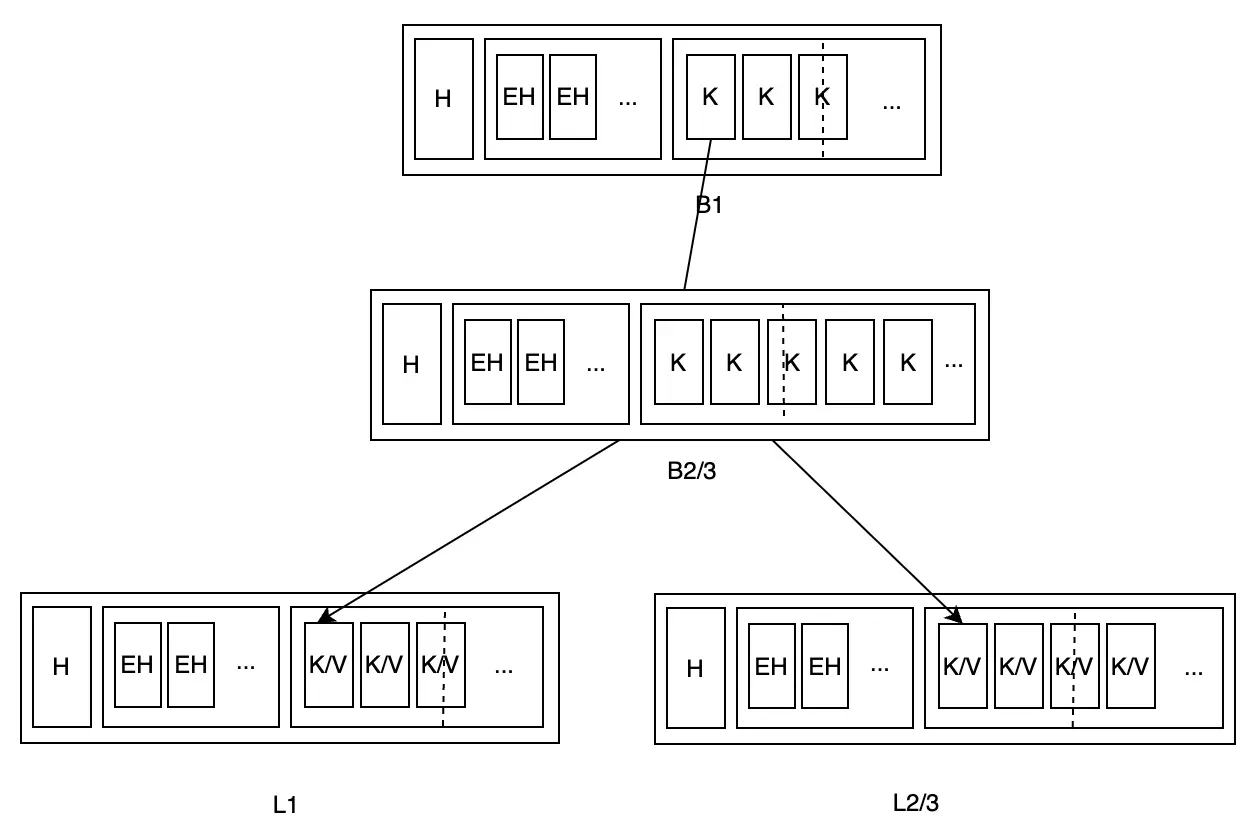
Nếu cần thiết, quá trình đệ quy như vậy sẽ tiếp tục cho đến root node. Còn có một trường hợp đặc biệt cần xem xét: khi root node là branch node và chỉ có một child node, child node duy nhất có thể được thăng cấp trực tiếp để trở thành root node, và root node ban đầu có thể được giải phóng.
Sau rebalance, cấu trúc cây trong bộ nhớ thỏa mãn: tỷ lệ fill dữ liệu của tất cả node đều lớn hơn FillPercent. Tuy nhiên, tỷ lệ fill của các node này có thể lớn hơn 100% rất nhiều, do đó cần các thao tác spill để kiểm soát tỷ lệ fill của tất cả node dưới FillPercent từ hướng ngược lại.
Spill
Spill theo nghĩa đen có nghĩa là “nước tràn ra từ thùng chứa vì quá đầy”. Ở đây nó chỉ việc node được chứa đầy quá nhiều dữ liệu, tràn ra nhiều node. Đây là ví dụ:
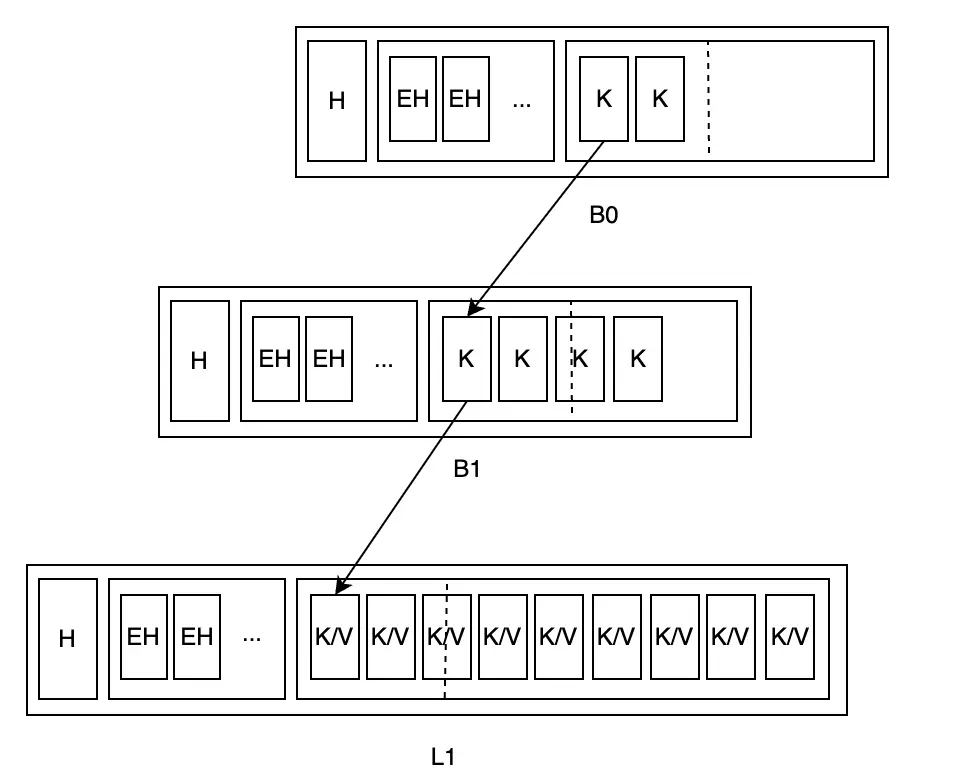
Rõ ràng, L1 có tỷ lệ fill quá cao, nên spill cần tách nó thành nhiều node (sử dụng hàm split):
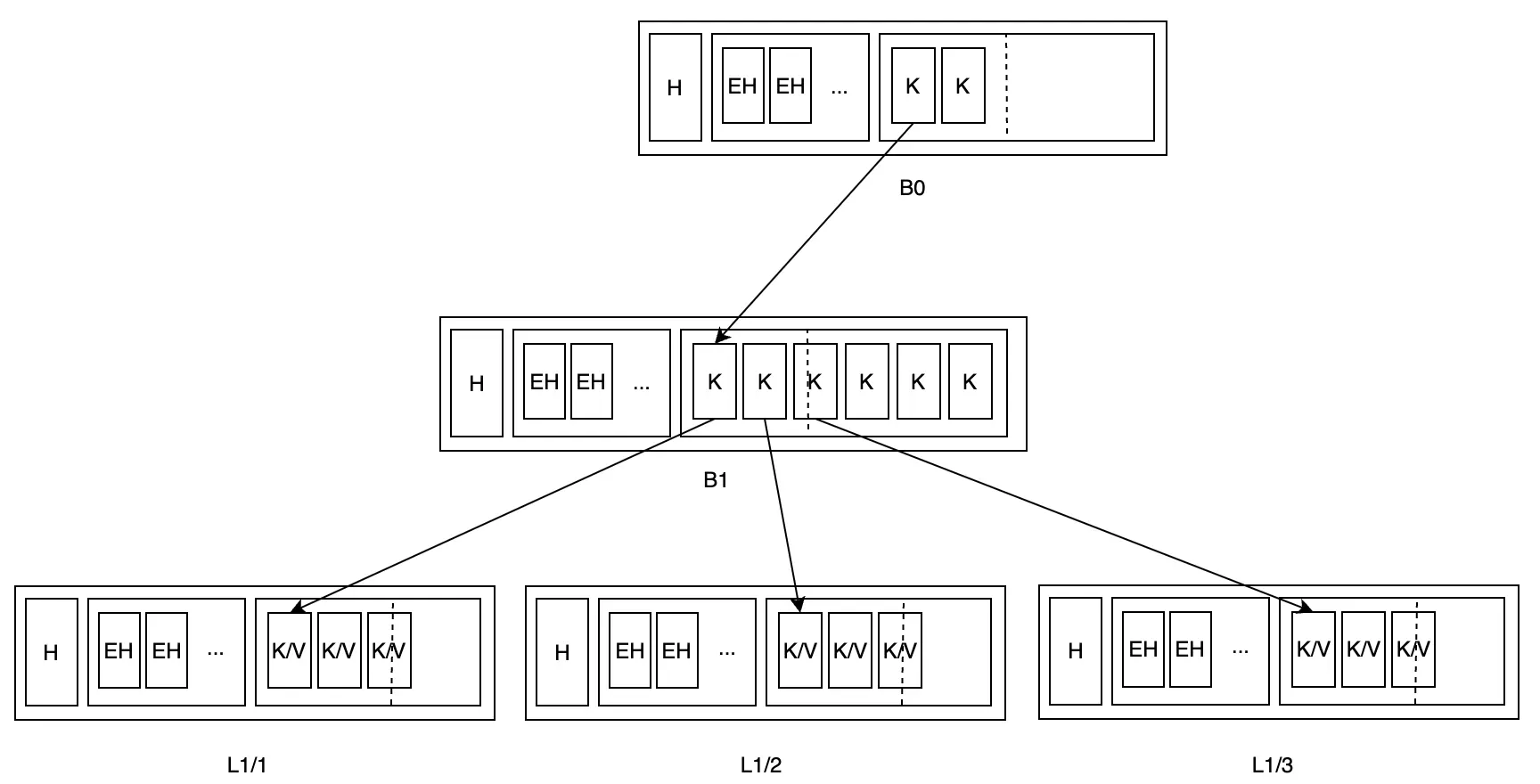
Quá trình tách L1 sẽ khiến tỷ lệ fill của parent node tăng lên, có thể gây ra việc tách parent node:
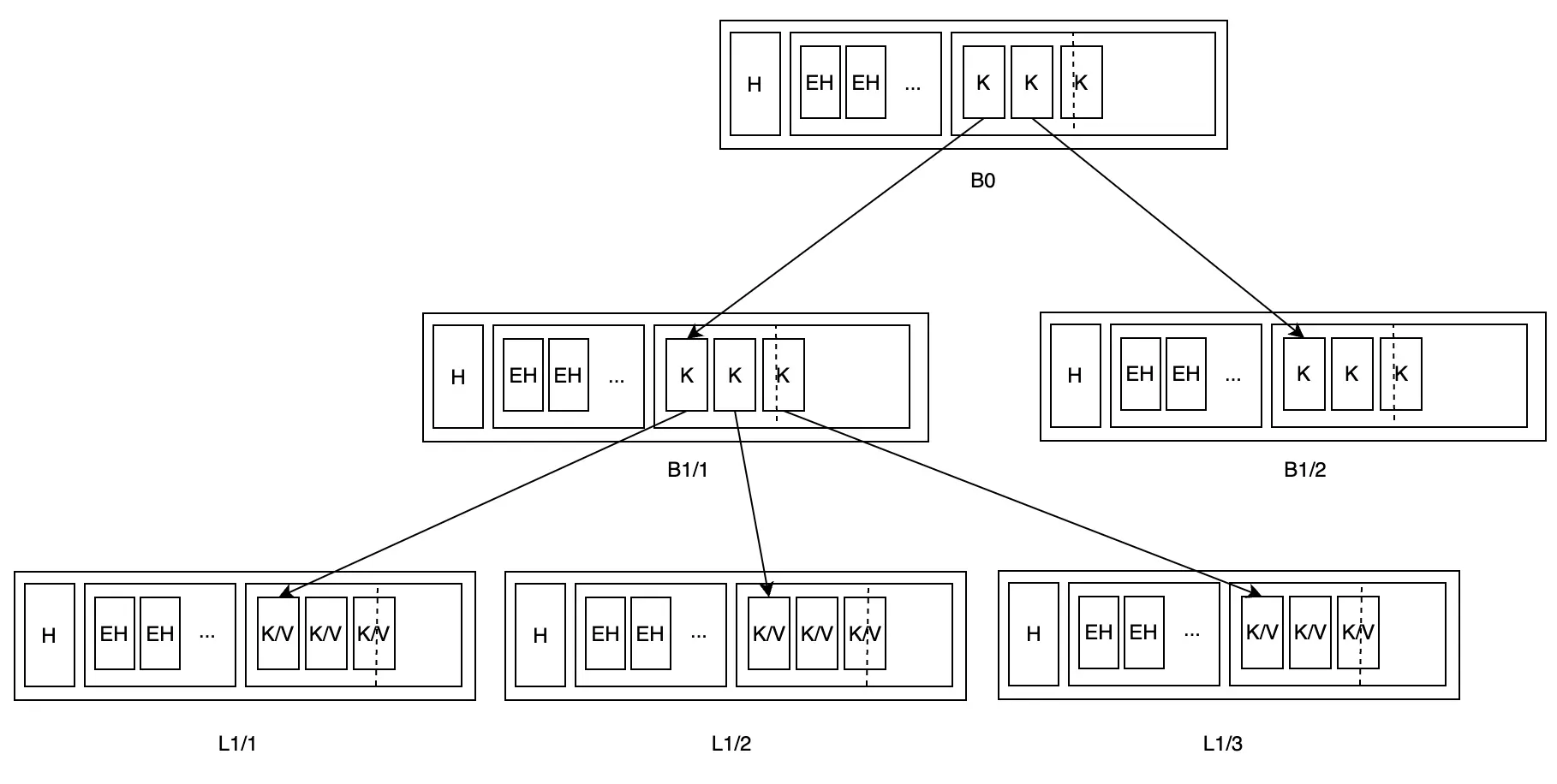
Nếu cần thiết, đệ quy như vậy sẽ đạt đến root node. Lý do parent node quá tải có thể không chỉ là quá nhiều cặp khóa-giá trị, mà cũng có thể là dữ liệu riêng lẻ quá lớn. Nếu là trường hợp sau, spill sẽ không tách node thêm nữa, mà sẽ giữ lại những node quá tải này:

Trong quá trình serialize, những node quá tải như vậy sẽ được chuyển đổi thành overflow page để lưu trữ.
Dereference
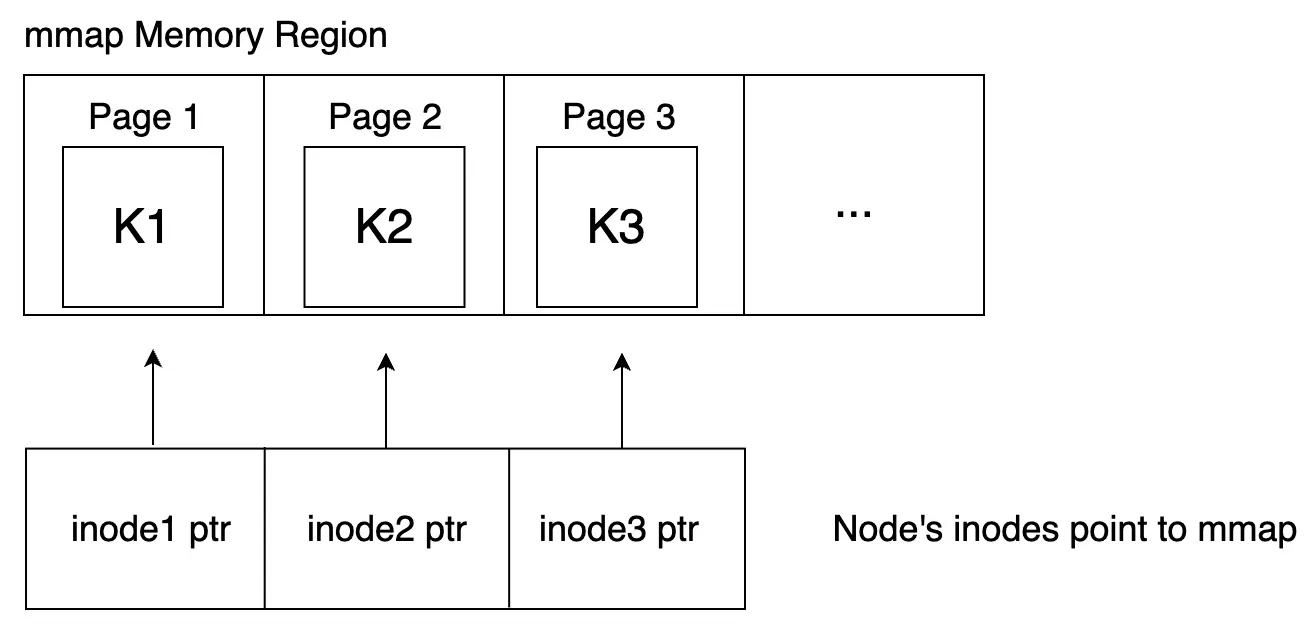
Bên cạnh đó, node cũng có một method đặc biệt liên quan đến việc kiểm soát dữ liệu in-memory, đó là dereference. Hàm này đơn giản chỉ copy toàn bộ data của node key và các inodes vào heap memory và chuyển reference đến nơi mới copy (mmap → heap). Lý do:
- Ban đầu, dữ liệu được load từ disk lên memory thông qua mmap. Lúc này, pointer của các inode đang trỏ trực tiếp đến vùng nhớ mà mmap đã allocate.
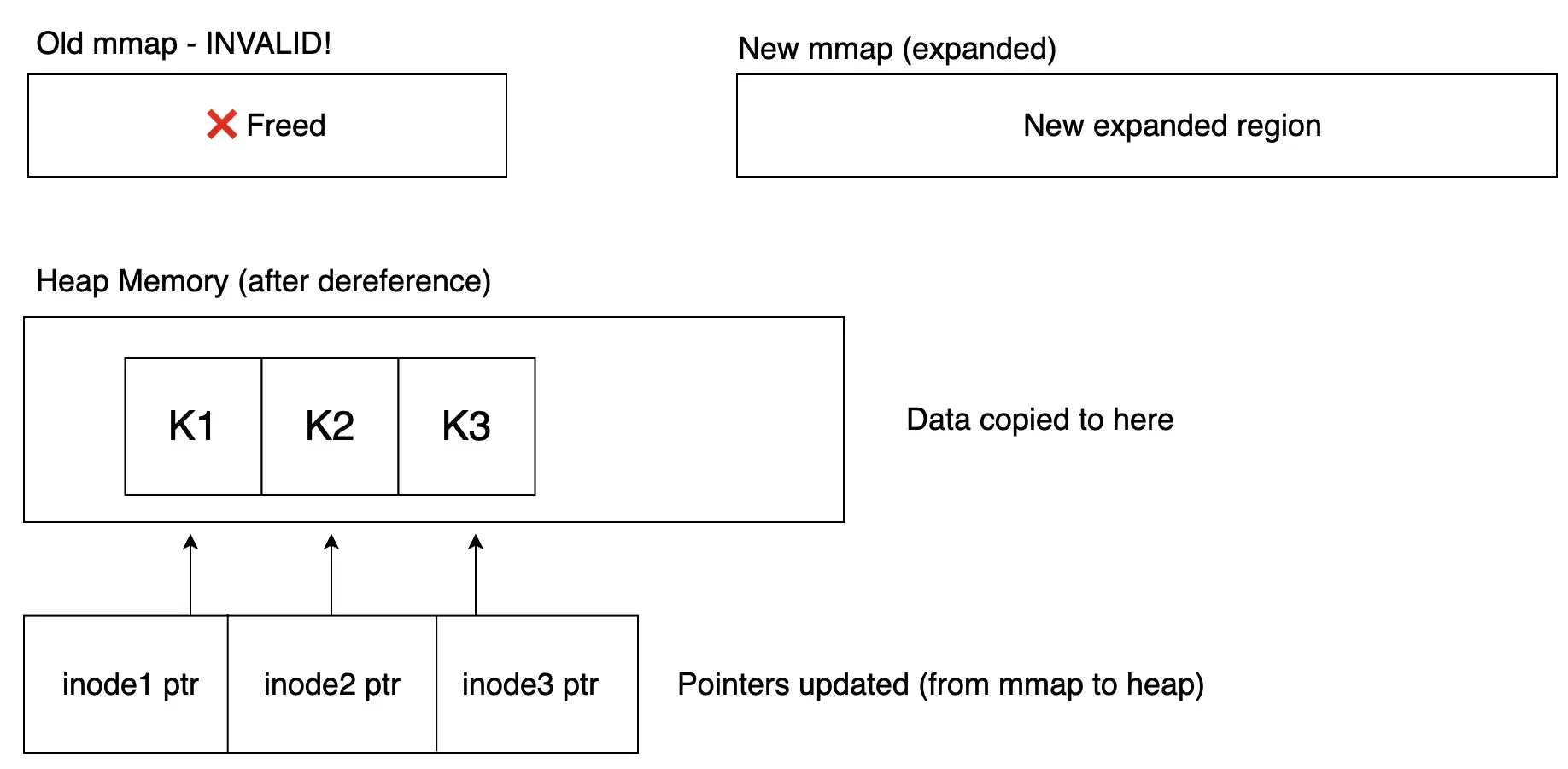
- Tuy nhiên, đến một lúc cần cấp phát một bộ nhớ lớn hơn kích thước mmap hiện tại, mmap sẽ đơn giản là chuyển sang một vùng nhớ mới lớn hơn, khiến vùng nhớ cũ ban đầu trở lên không hợp lệ. Lúc này ta cần một cơ chế để giúp các inode vẫn trỏ đến đúng vùng nhớ chứa data hợp lệ như ban đầu. Vì vậy, dereference ra đời khi ta cần allocate lại một vùng nhớ mới có sử dụng đến mmap (vì nếu freelist còn đủ thì không việc gì phải allocate lại mmap cả).
Kết
Ơ mây zing gút chóp! Giờ ta đã hiểu cách B+ Tree tổ chức và tìm kiếm key-value pairs hiệu quả. Nhưng trong thực tế, một application thường không chỉ lưu một loại dữ liệu. Ví dụ: ta cần lưu cả user data, session data, config data… Làm sao để tổ chức nhiều “namespaces” khác nhau trong cùng một database file mà không bị conflict?
Đây chính là lúc Bucket System ra đời - một abstraction layer cho phép ta tạo nhiều “containers” độc lập trong cùng một Bolt database. Phần sau ta sẽ tìm hiểu nó nhé.