- Published at
Build một cái K-V Database đơn giản như thế nào? (P4 - Bucket)

Tìm hiểu về cấu trúc Bucket trong Bolt DB - container lưu trữ K-V data với khả năng lồng ghép vô hạn và tối ưu hóa không gian với inline-bucket
Table of Contents
Bucket là container cho K-V data trong Bolt. Chúng ta có thể tạo các bucket khác nhau trong cùng một instance Bolt để lưu trữ các loại dữ liệu khác nhau. Bucket cũng hỗ trợ lồng ghép vô hạn, nghĩa là có thể tạo sub-bucket trong bucket, cung cấp cho dev giải pháp linh hoạt hơn để phân loại dữ liệu.
Cấu trúc cơ bản của một Bucket
Mỗi bucket trong Bolt đều có thể lưu trữ cả sub-bucket và K-V data. Nhờ vào thiết kế này, một instance Bolt chỉ cần tạo một root bucket (bucket gốc) khi khởi tạo. Tất cả các bucket và cặp K-V do người dùng tạo sẽ được lưu trong root bucket, tạo thành cấu trúc cây lồng nhau.
Thử tạo một bucket mới với tên bucket1:
func main() {
db, _ := bolt.Open("1.db", 0600, nil)
defer db.Close()
_ = db.Update(func(tx *bolt.Tx) error {
_, err := tx.CreateBucketIfNotExists("bucket1")
})
}
Bolt chèn một cặp K-V mới vào root bucket, trong đó key là "bucket1" và value là instance bucket này, như hình dưới đây:
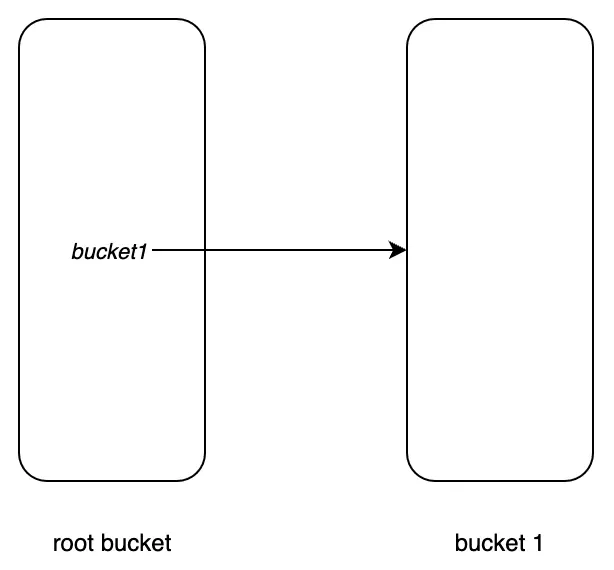
Tiếp tục tạo bucket2 và bucket3, ta được:
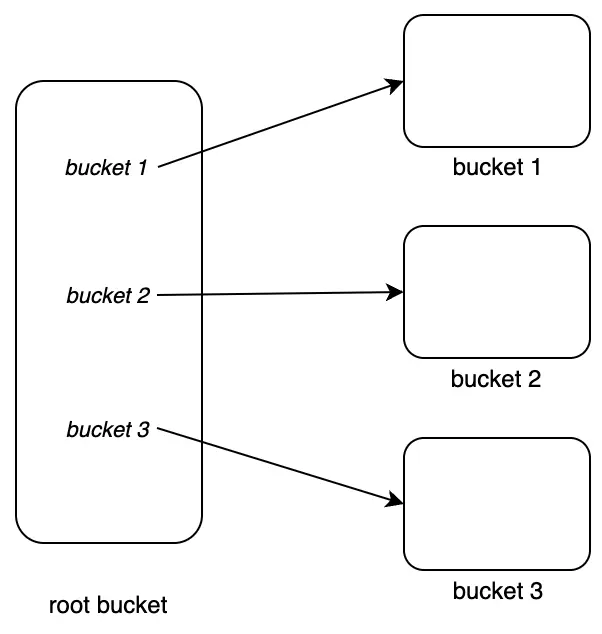
Chèn dữ liệu K-V {k1: v1} và {k2: v2} vào bucket2, ta được:
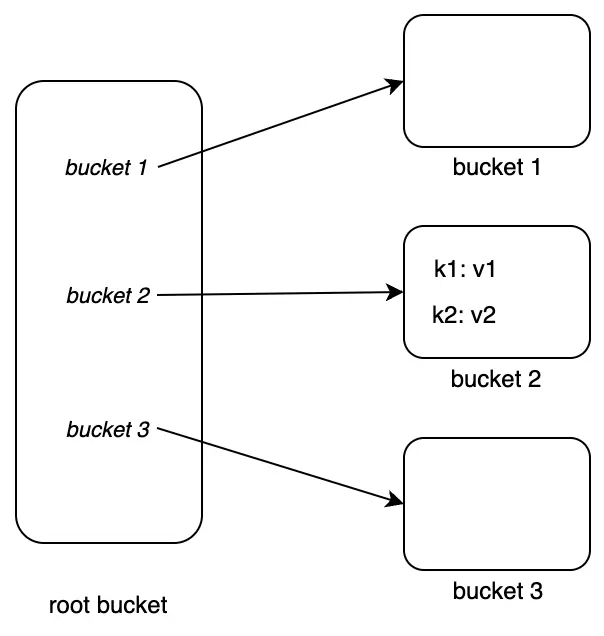
Tiếp tục tạo hai sub-bucket bucket 23 và bucket 24 trong bucket2, ta được:
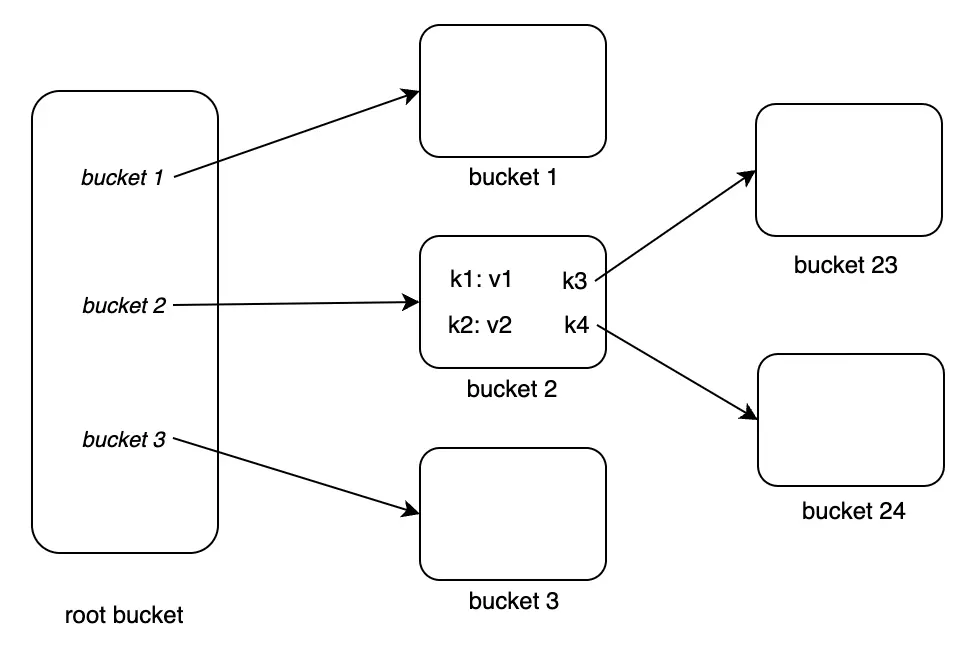
Trong hình trên, chúng ta đã thấy hình dạng của một cây.
Cấu trúc vật lý của một Bucket:
Trong phần Data Structure đã giới thiệu rằng Bolt sử dụng B+ Tree để lưu trữ chỉ mục và dữ liệu thô. Vậy làm thế nào để sử dụng B+ Tree để triển khai bucket? Hãy bắt đầu từ trường hợp đơn giản nhất:
Khởi tạo DB
Khi khởi tạo instance mới, Bolt tạo root bucket. Điều này có thể thấy trong phương thức khởi tạo của DB:
func (db *DB) init() error {
buf := make([]byte, db.pageSize*4)
for i := 0; i < 2; i++ {
// ...
// Initialize the meta page.
m := p.meta()
// ...
m.root = bucket{root: 3}
// ...
}
// ...
// Write an empty leaf page at page 4
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count = 0
// ...
}
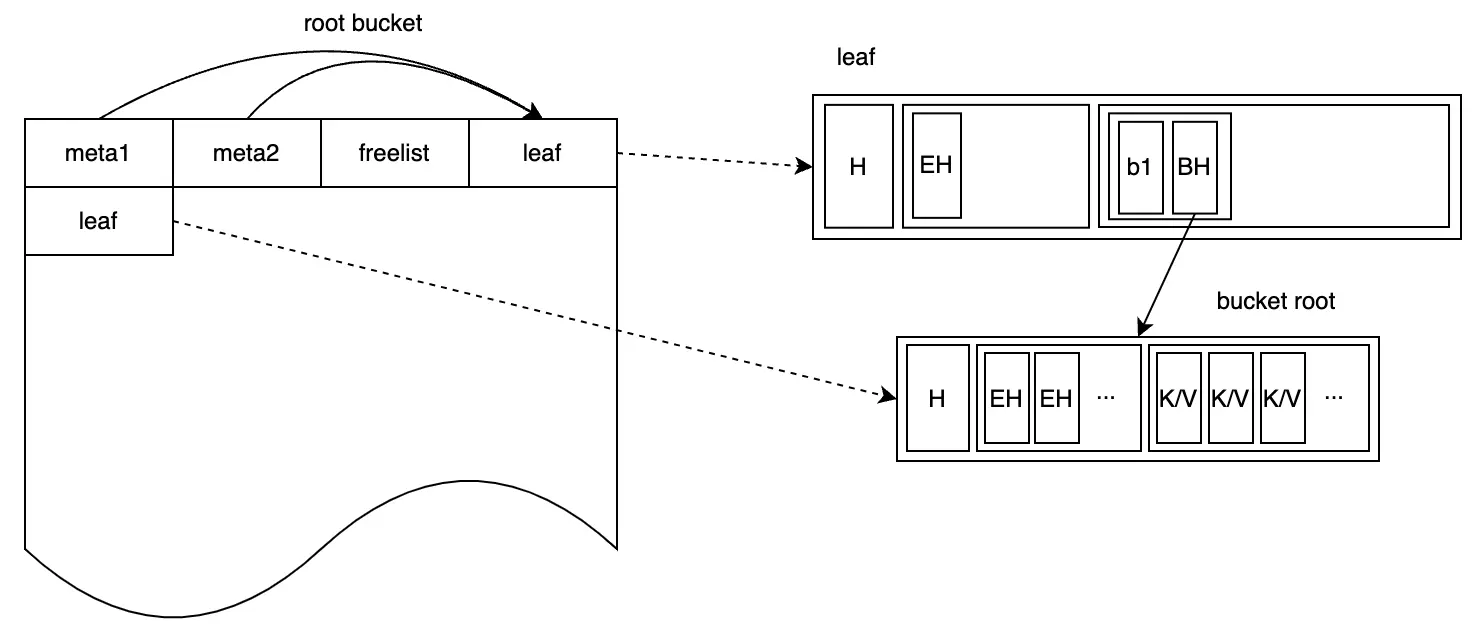
Thông tin root bucket được lưu trong meta page. Sau khi khởi tạo, root bucket trỏ tới một leaf page trống, cái mà sẽ trở thành container cho tất cả sub-bucket và K-V data do người dùng tạo, như hình dưới đây:
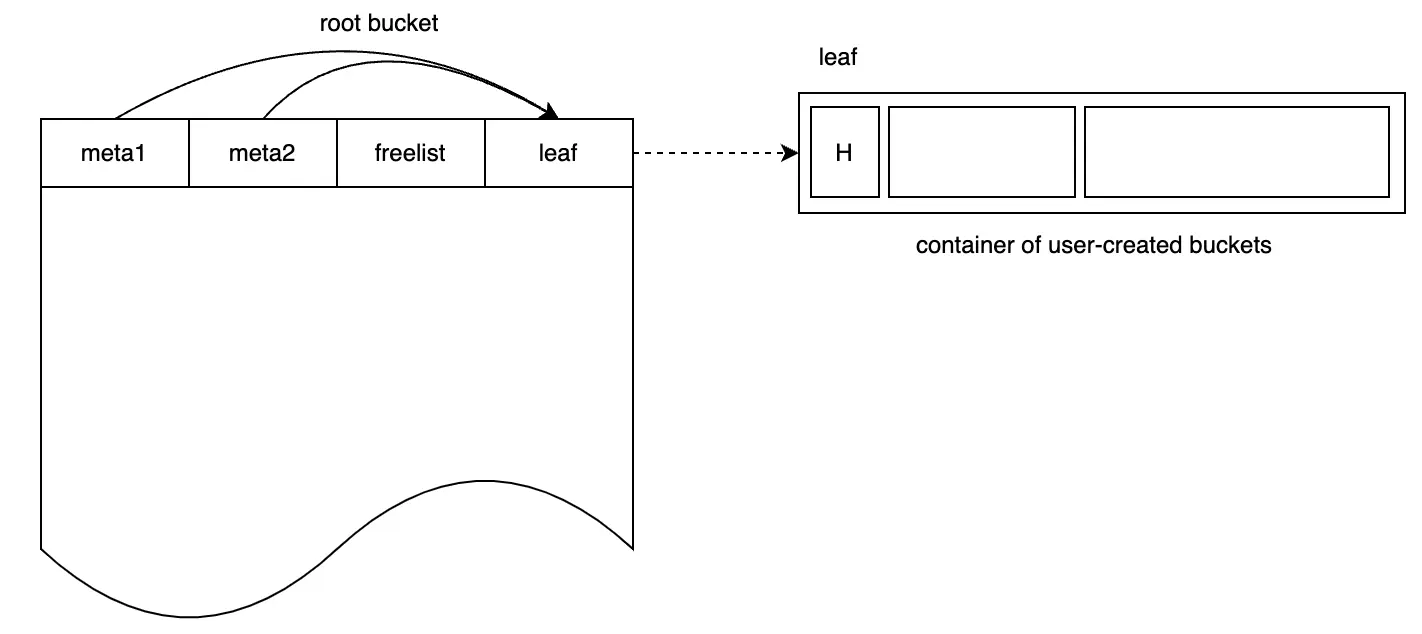
Tạo một Bucket
Giả sử sau khi người dùng khởi tạo instance Bolt, họ tạo một bucket có tên "b1". Điều này được thể hiện trong hình như sau:
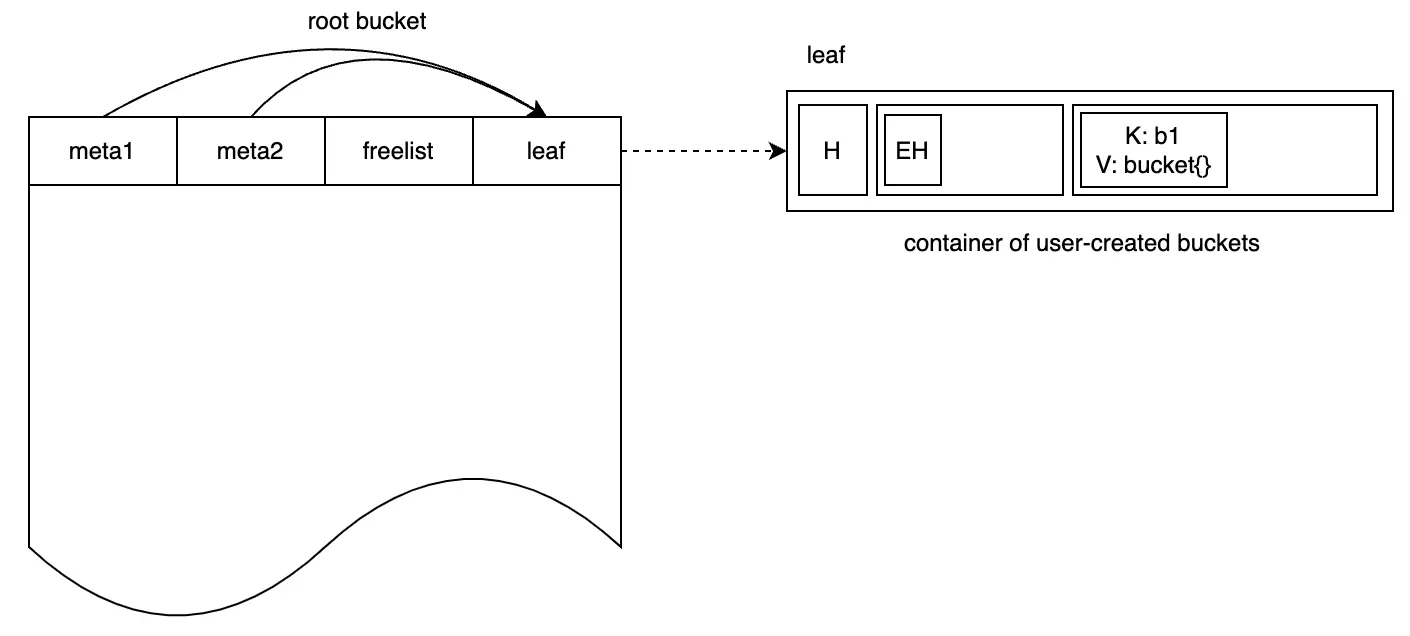
Một cặp K-V được thêm vào leaf page, trong đó key là b1 và giá trị là một instance bucket. Định nghĩa cấu trúc của instance bucket như sau:
type bucket struct {
root pgid // page id của page root-level của bucket
sequence uint64 // tăng đơn điệu, được sử dụng bởi NextSequence()
}
Ở đây, root trỏ tới page id của node gốc của bucket đó. Tuy nhiên, nếu chúng ta cấp phát một page riêng cho mỗi bucket mới, trong các case cần sử dụng nhiều bucket nhỏ, sẽ tạo ra phân mảnh nội bộ (internal fragment) gây lãng phí disk space.
Lấy ví dụ từ nested-bucket: giả sử chúng ta sử dụng Bolt làm cơ sở dữ liệu cho một multi-tenant service. Dịch vụ này cần một bucket tenant để lưu trữ dữ liệu của mỗi service, và mỗi service bên trong chứa các sub-bucket khác như Users, Notes, v.v. Giả sử việc sử dụng thực tế tuân theo luật lũy thừa, 80% tenant data chỉ chiếm 20% total data volume. Trong trường hợp này, nếu chúng ta cấp phát page mới cho sub-bucket của các tenant nhỏ này, có thể gây lãng phí disk space.
Bolt sử dụng inline-bucket để giải quyết vấn đề trên. Inline-bucket không chiếm một page riêng biệt; nó là một page ảo, nhưng về logic nó là một page. Mỗi inline-page cũng chứa page header, element header và data. Khi lưu trữ, nó sẽ được tuần tự hóa thành dữ liệu nhị phân thông thường và được lưu trữ như K-V data cùng với tên bucket.
Thực tế, tất cả các bucket mới tạo, bao gồm b1 vừa tạo, đều là inline-bucket. Bolt tận dụng tính năng pgid bắt đầu từ 1, sử dụng pgid = 0 để biểu thị inline-bucket. Do đó, hình trên có thể được tinh chỉnh như sau:
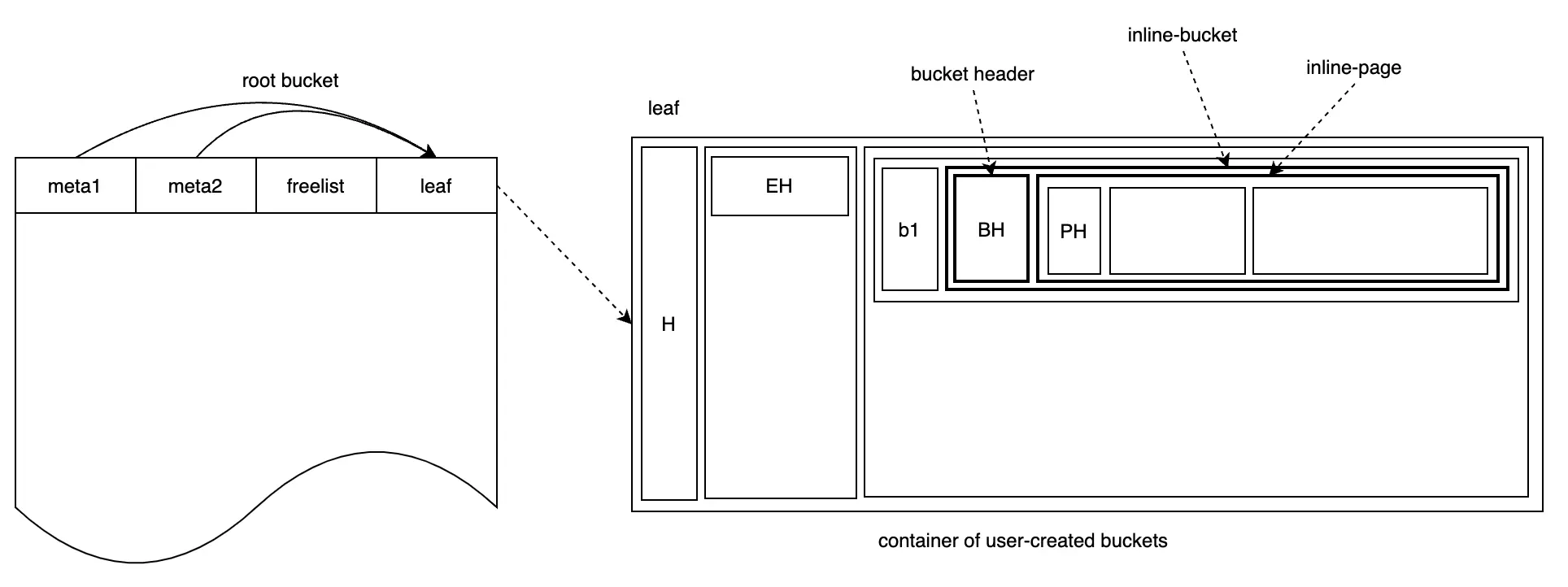
Chèn cặp K-V {k1:v1} vào bucket b1 có thể được biểu thị như sau:
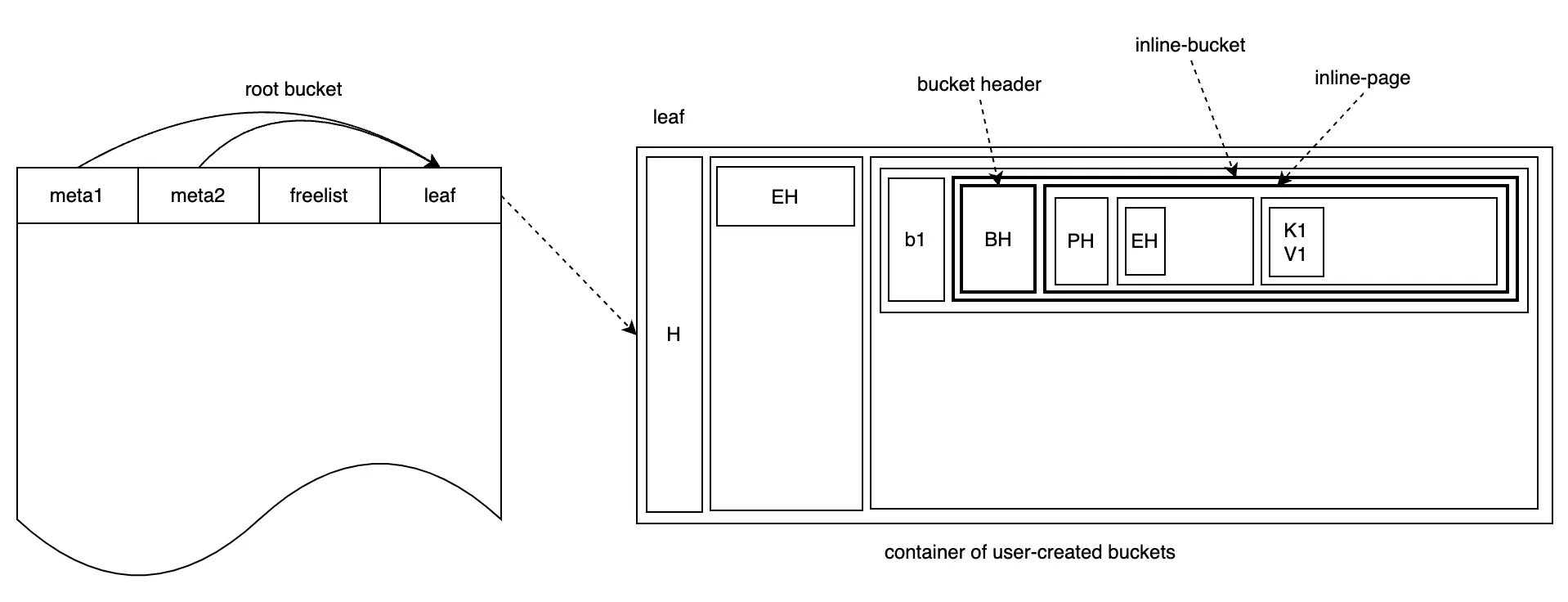
Chèn thêm K-V data
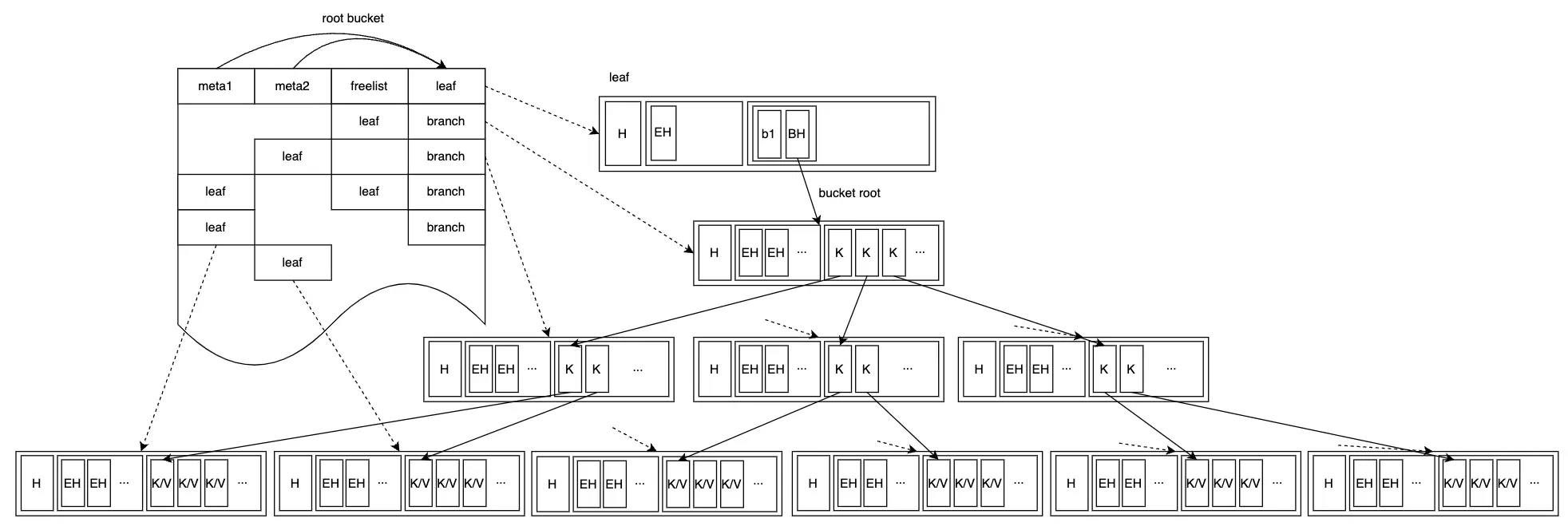
Khi dữ liệu trong bucket b1 đạt tới một lượng nhất định, tức là vượt quá giới hạn kích thước của inline-bucket, inline-bucket sẽ được chuyển đổi thành bucket bình thường và có thể được cấp phát page riêng của nó, như hình dưới đây:
Chèn thêm K-V data, bucket b1 sẽ phát triển thành B+ Tree pr0 max hơn:
Tạo thêm Bucket:
Giả sử người dùng tiếp tục tạo thêm bucket giống như b1, cho đến khi một leaf node không thể chứa tất cả child node của root bucket. Lúc này, root bucket cũng sẽ phát triển thành B+ Tree pr0 max hơn:
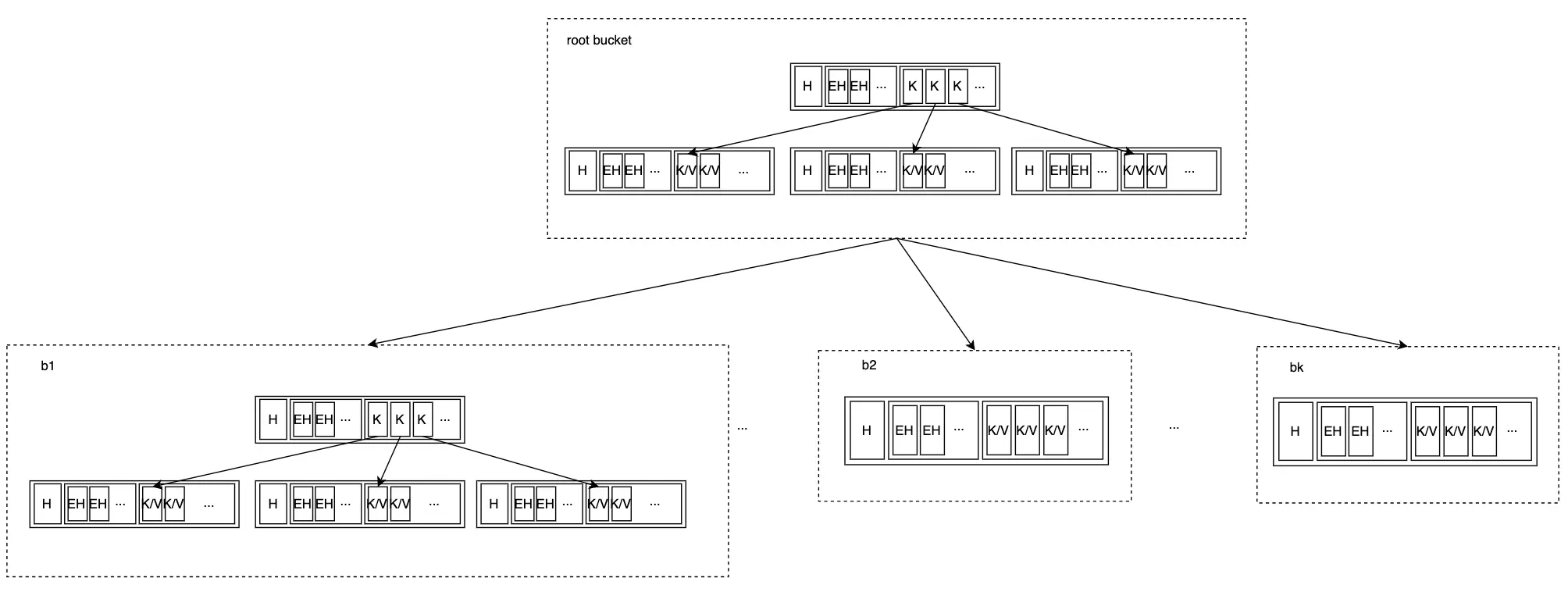
Cần lưu ý rằng mặc dù dữ liệu trong mỗi bucket là B+ Tree hợp lệ, nhưng cây mà chúng cùng nhau tạo thành thường không phải là B+ Tree.
Kết
Bucket System giải quyết được việc tổ chức dữ liệu thành các namespace riêng biệt. Nhưng khi đã có data được group gọn gàng trong các buckets, một thách thức mới xuất hiện: làm sao để traverse qua nhiều K-V pairs một cách hiệu quả?
Đây chính là lúc Cursor ra đời - một iterator cho phép navigate qua B+ Tree một cách hiệu quả. Ta sẽ tìm hiểu nó ở phần sau.