- Published at
Build một cái K-V Database đơn giản như thế nào? (P5 - Cursor)

Tìm hiểu về Cursor trong Bolt DB - cấu trúc dữ liệu quan trọng cho việc duyệt và truy cập tuần tự/ngẫu nhiên dữ liệu trong B+ Tree
Table of Contents
Phần trước ta đã tìm hiểu về Bucket, nó là 1 container chứ toàn là K-V data và sub-bucket. Vậy khi dữ liệu được tổ chức theo cấu trúc B+ Tree mà trên đó data chỉ nằm ở các leaf node, làm sao để có thể duyệt data trên Bucket hiệu quả khi cấu trúc gồm cả branch và leaf node? Lúc này, ta cần một cấu trúc dữ liệu đặc biệt để hỗ trợ việc truy cập dữ liệu trở nên đơn giản và nhanh chóng hơn.
Cursor là cấu trúc dữ liệu thiết yếu trong Bolt, cung cấp khả năng truy cập tuần tự và ngẫu nhiên đến K-V data trong các bucket. Chúng hoạt động như các iterator duy trì thông tin vị trí khi duyệt qua cấu trúc B+ Tree, cho phép điều hướng hiệu quả qua các cặp K-V đã được sắp xếp.Cursor là cơ chế chính để đọc dữ liệu từ bucket và hỗ trợ cả việc lặp tiến và lùi.
Cấu trúc và thiết kế Cursor
Cursor trong Bolt được thiết kế như một iterator nhẹ duy trì vị trí của nó trong cấu trúc B+ Tree của bucket:
type Cursor struct {
bucket *Bucket // Tham chiếu đến bucket đang được duyệt
stack []elemRef // Một stack các elemRef để track đường dẫn hiện tại từ root đến leaf trong B+ tree
}
type elemRef struct {
page *page // Tham chiếu đến trang vật lý
node *node // Tham chiếu đến node in-mem (nếu đã được materialize)
index int // Vị trí trong page/node
}
Chú ý ở elemRef , có 2 field là page và node. Tuy nhiên ta chỉ sử dụng một trong 2 field này vì:
- Nếu node đã được load lên memory rồi thì page = null.
- Ngược lại thì node = null.
Field index trong elemRef cũng có 2 cách sử dụng tuỳ thuộc vào elemRef hiện tại là của branch hay leaf node/page:
- Nếu là branch: Chỉ số của
child pointerđể phục vụ việc trace tiếp theo. - Nếu là leaf: Chỉ số của
cặp key/valueđang được tham chiếu.
Đặt stack vào cấu trúc giúp cursor thuận tiện ghi lại thông tin vị trí từ lần trước. Vì các node trung gian của B+ Tree không trực tiếp lưu trữ K-V data nên quá trình duyệt không có sự khác biệt giữa pre-order, in-order và post-order.
Phân biệt Bucket và Key-Value
Như phần Bucket, ta đã tìm hiểu về cách lưu trữ cách sub-bucket trên trực tiếp leaf node. Một trong những khía cạnh quan trọng của hoạt động cursor là sự phân biệt giữa nested bucket và các cặp key-value thông thường. Khi cursor gặp một entry bucket, nó hoạt động khác so với dữ liệu thông thường.
Đơn giản, Cursor sử dụng flag đã được dùng để define ở header của các inline-bucket. Nếu khớp flag, value sẽ được gán bằng nil. Chúng ta có thể thấy điều này qua ví dụ sau:
func main() {
_ = db.Update(func(tx *bolt.Tx) error {
b1, _ := tx.CreateBucketIfNotExists([]byte("b1"))
_, _ = b1.CreateBucketIfNotExists([]byte("b11"))
_ = b1.Put([]byte("k1"), []byte("v1"))
_ = b1.Put([]byte("k2"), []byte("v2"))
return b1.ForEach(func(k, v []byte) error {
fmt.Printf("key: %s, val: %s, nil: %v\n", k, v, v == nil)
return nil
})
})
}
// Tiến hành chạy chương trình, kết quả in ra:
key: b11, val: , nil: true
key: k1, val: v1, nil: false
key: k2, val: v2, nil: false
Các loại truy cập
Vì tất cả dữ liệu trên B+ Tree được sắp xếp theo thứ tự byte của key, nên quá trình tìm kiếm tương tự như cây tìm kiếm nhị phân. Khác với cây tìm kiếm nhị phân, các node riêng lẻ trong B+ Tree thường lớn hơn và lưu trữ nhiều dữ liệu hơn, do đó tìm kiếm nhị phân được sử dụng khi tìm kiếm trong một node để nâng cao hiệu quả tìm kiếm.
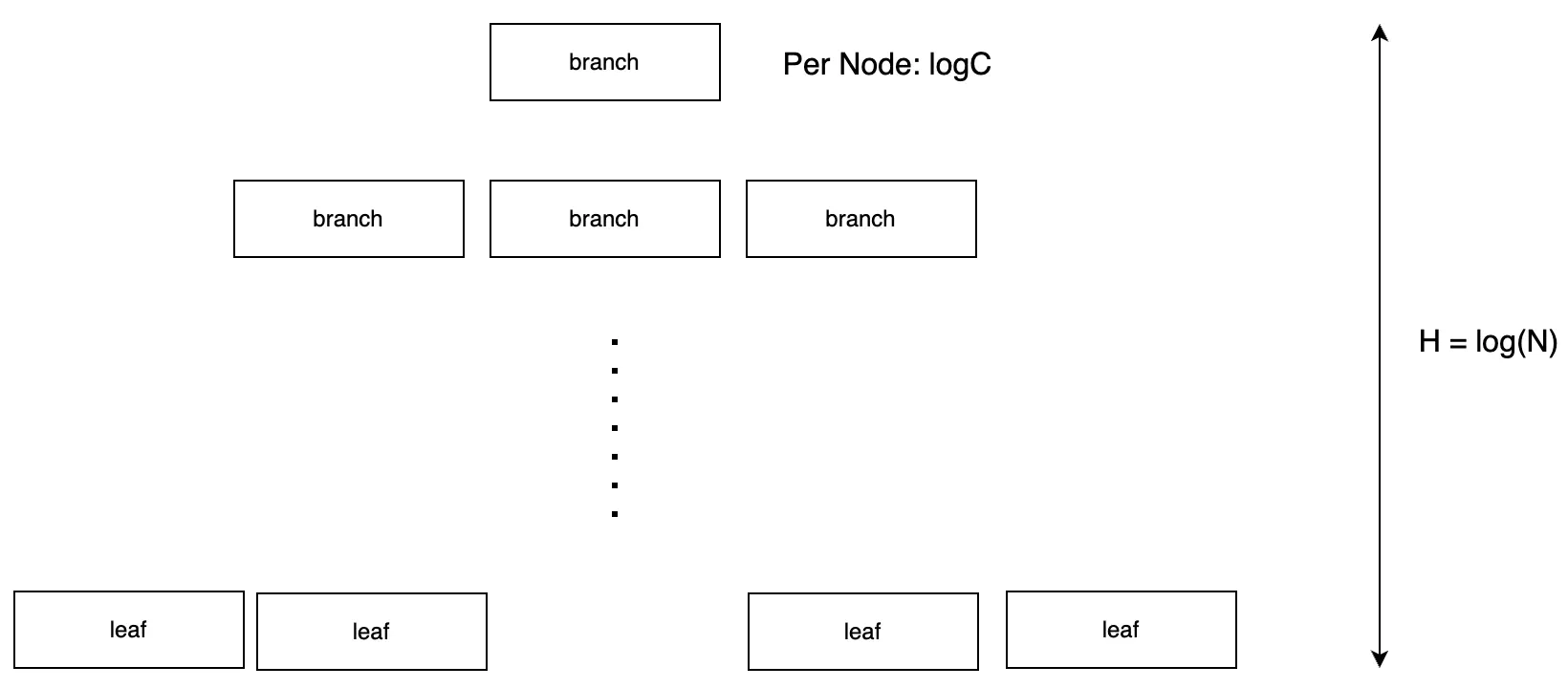
Giả sử tổng số dữ liệu là N, và giới hạn trên của số cặp K-V mà một node có thể chứa là C. Khi đó độ phức tạp tìm kiếm của một node là O(log(C)), chiều cao cây là log(N) như hình vẽ sau:
Truy cập tuần tự
Các phương thức truy cập tuần tự cho phép duyệt dữ liệu theo thứ tự key đã sắp xếp:
// Di chuyển đến cặp key-value đầu tiên trong bucket
func (c *Cursor) First() (key []byte, value []byte)
// Di chuyển đến cặp key-value cuối cùng trong bucket
func (c *Cursor) Last() (key []byte, value []byte)
// Di chuyển đến cặp key-value tiếp theo
func (c *Cursor) Next() (key []byte, value []byte)
// Di chuyển đến cặp key-value trước đó
func (c *Cursor) Prev() (key []byte, value []byte)
Các phương thức này triển khai thuật toán duyệt tree được tối ưu hóa cho B+ Tree. Việc triển khai sử dụng stack của cursor để di chuyển hiệu quả giữa các vị trí mà không cần duyệt tree đầy đủ cho mỗi thao tác.
Với First và Last, ta cần truy vấn bắt đầu từ root xuống tới tận leaf node, với mỗi node đi qua, ta chỉ sử dụng key đầu tiên nên không tốn thêm chi phí tìm kiếm trên mỗi node. Vì vậy, độ phức tạp có thể quy thành O(logN).
Với Next và Prev, ta chỉ đơn giản di chuyển đến phần tử tiếp theo trong cùng một leaf node, hoặc đơn giản chỉ cần move lên một branch node để di chuyển xuống leaf node tiếp theo. Và trường hợp đen nhất là data nằm ở một page xa lắc phía bên kia như ví dụ dưới đây. Vì vậy, độ phức tạp trung bình có thể được coi như O(1).
Cùng xem xét một ví dụ đen đủi với Next như sau:
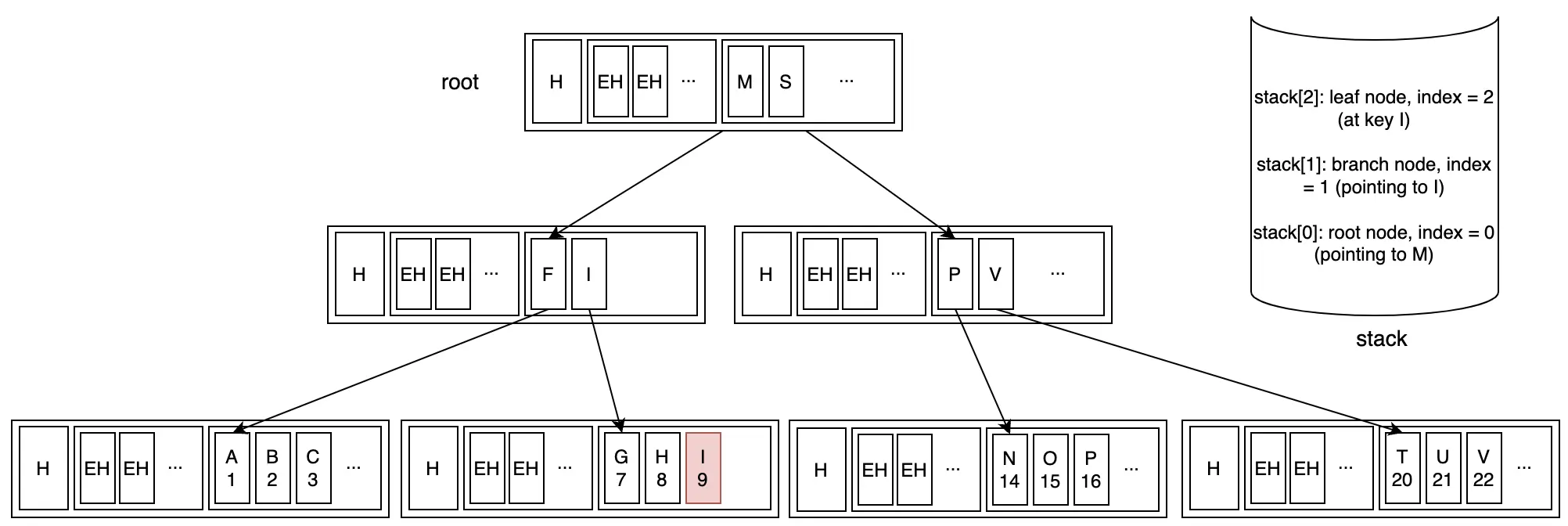
Cursor đang ở vị trí cuối cùng của một leaf node. Khi gọi Next(), cursor phải:
Bước 1: Di chuyển lên branch node cha, lúc này ta cần remove leaf node trong stack.
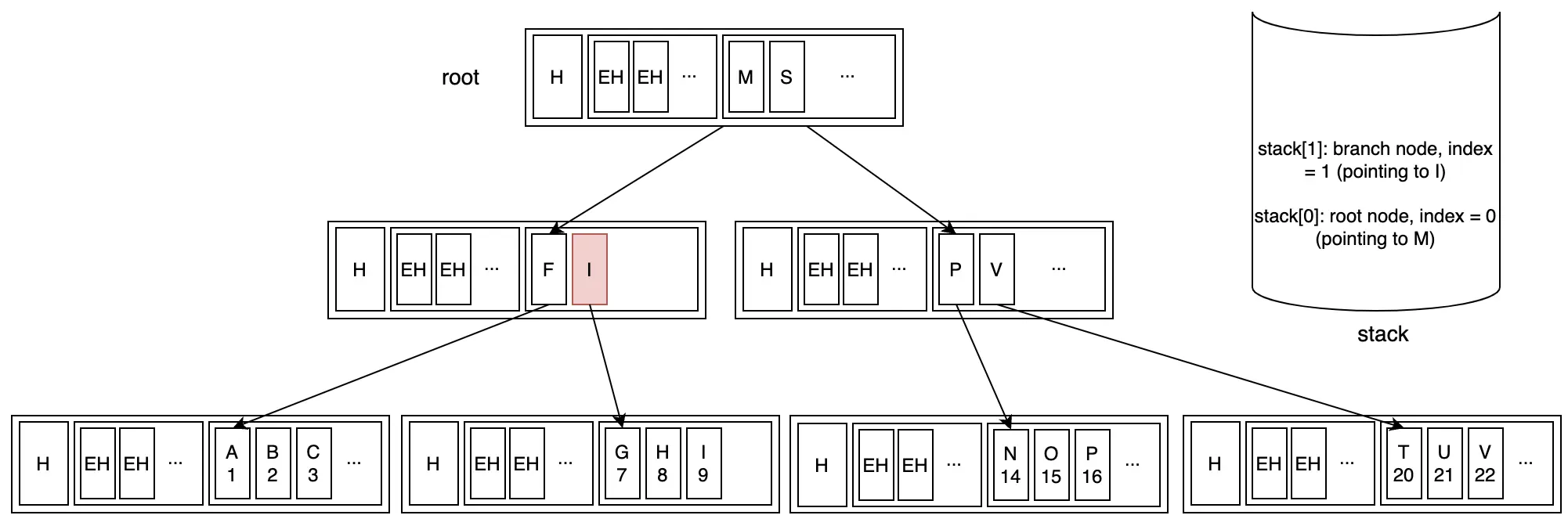
Bước 2: Di chuyển lên root node vì key ở branch node hiện tại đã là last key. Lúc này ta cũng cần remove branch node ra khỏi stack.
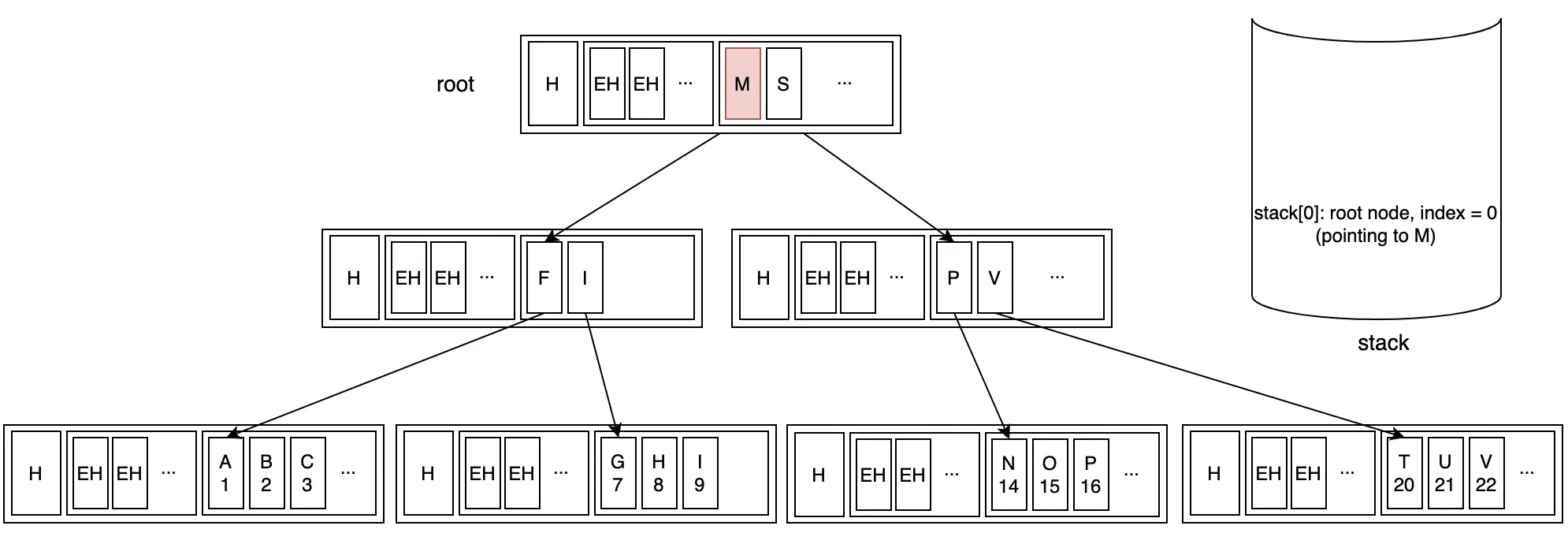
Bước 3: Chuyển qua key tiếp theo trên root node. Lúc này ta cập nhật lại dữ liệu trên stack
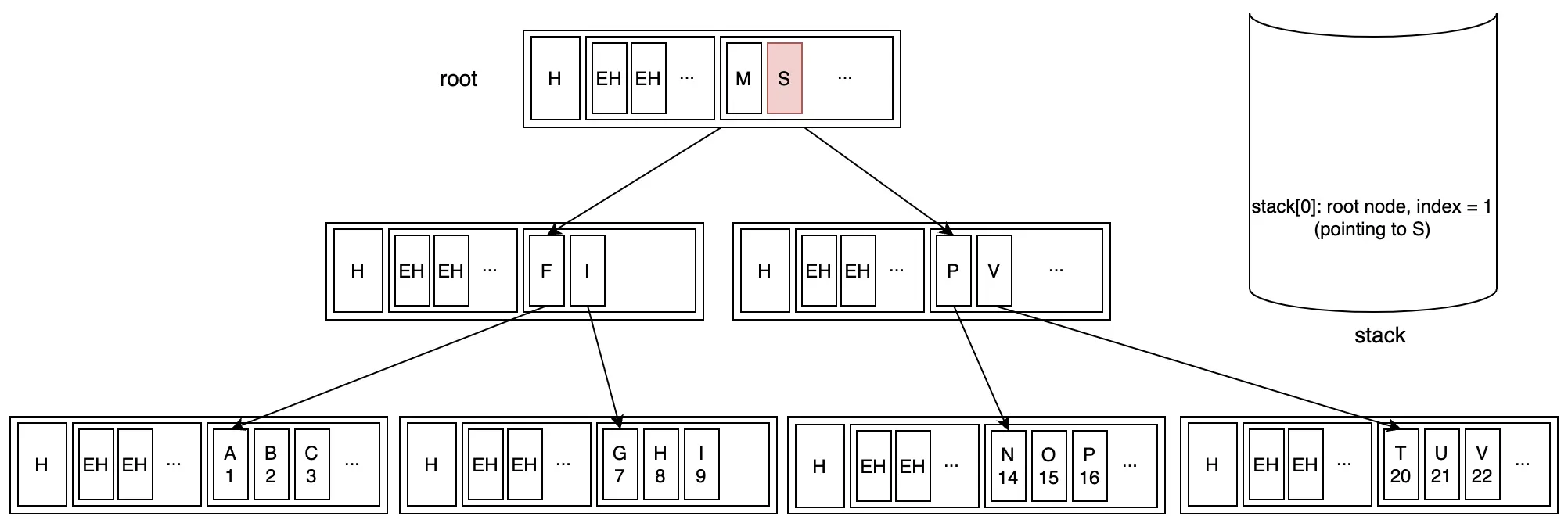
Bước 4: Di chuyển xuống branch node đầu tiên của root key mới. Đồng thời thêm branch node vào stack.
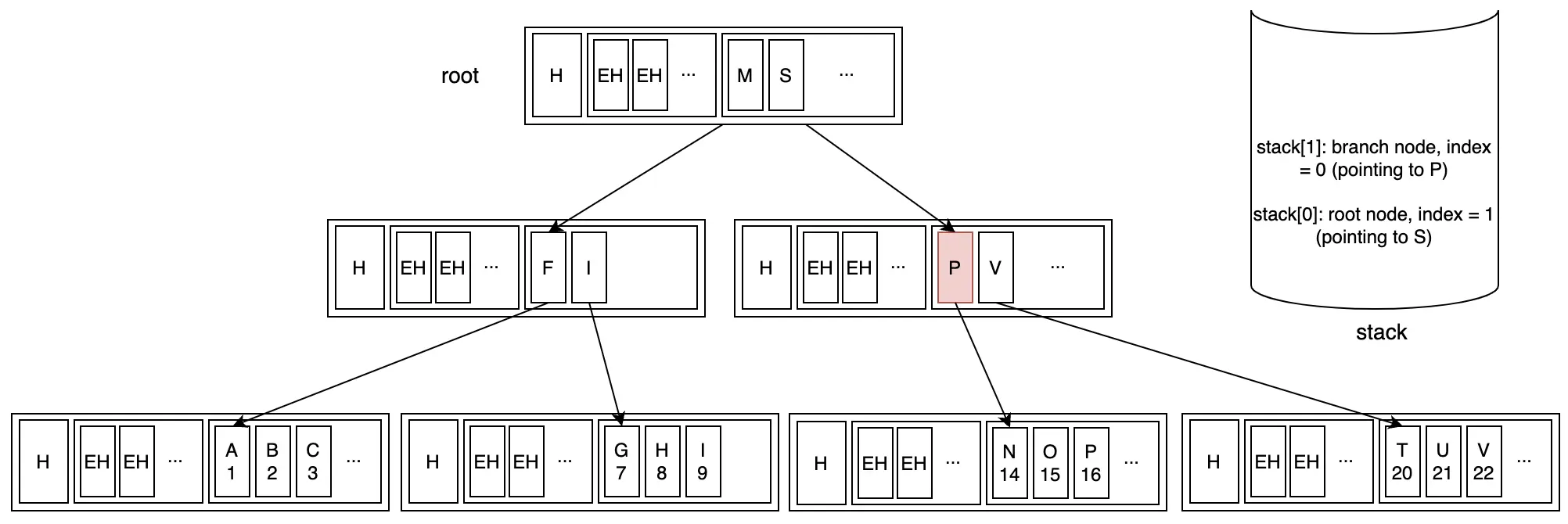
Bước 5: Đến vị trí đầu tiên trong leaf node mới
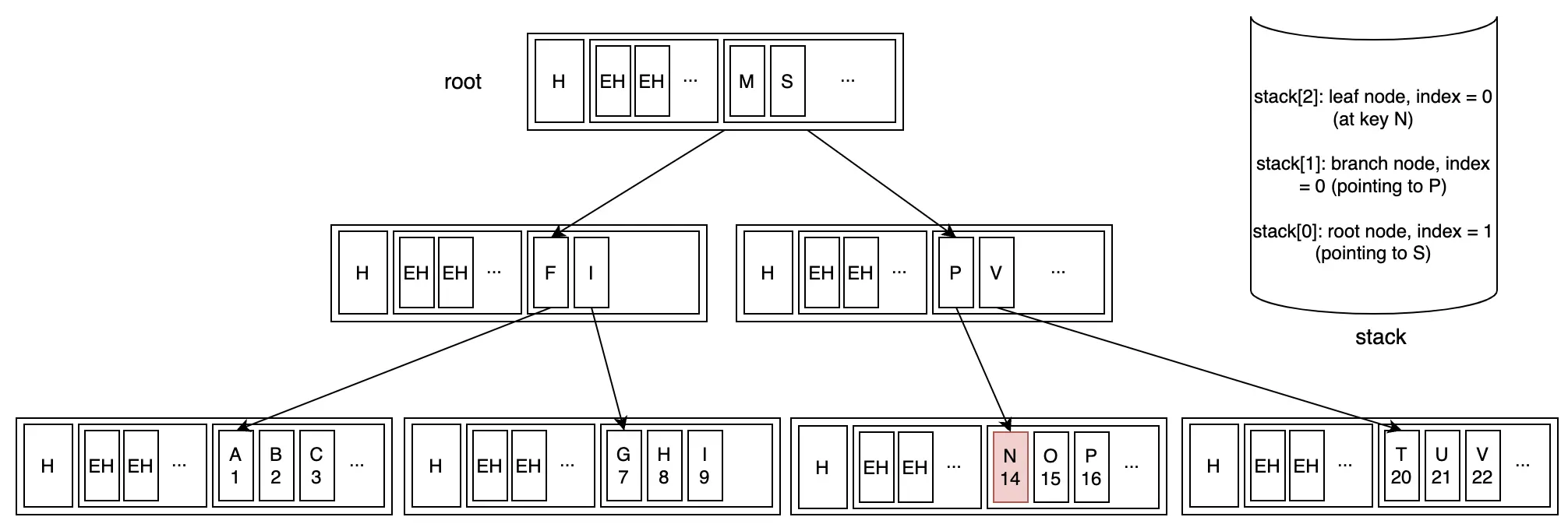
Truy cập ngẫu nhiên
Truy cập ngẫu nhiên được thực hiện thông qua phương thức Seek():
// Tìm kiếm key cụ thể và di chuyển cursor tới vị trí đó
func (c *Cursor) Seek(seek []byte) (key []byte, value []byte)
Xét ví dụ tìm kiếm key "V" với init state như sau:
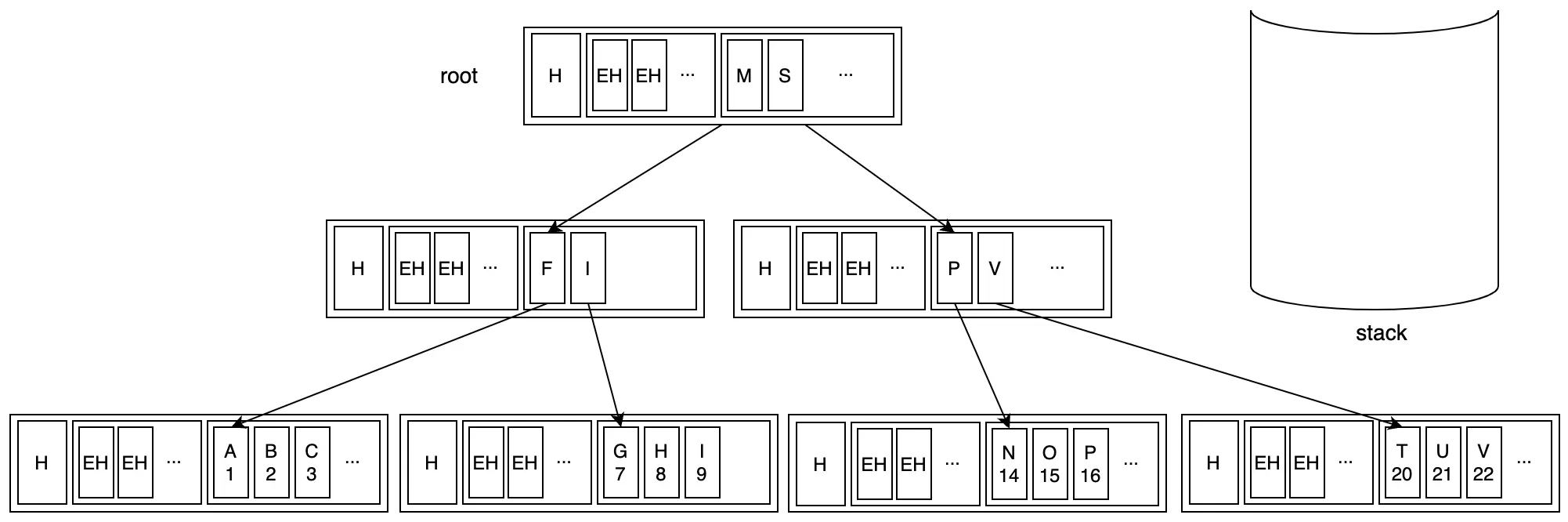
Bước 1: Bắt đầu từ root node, tìm kiếm nhị phân để xác định child node chứa key "V"
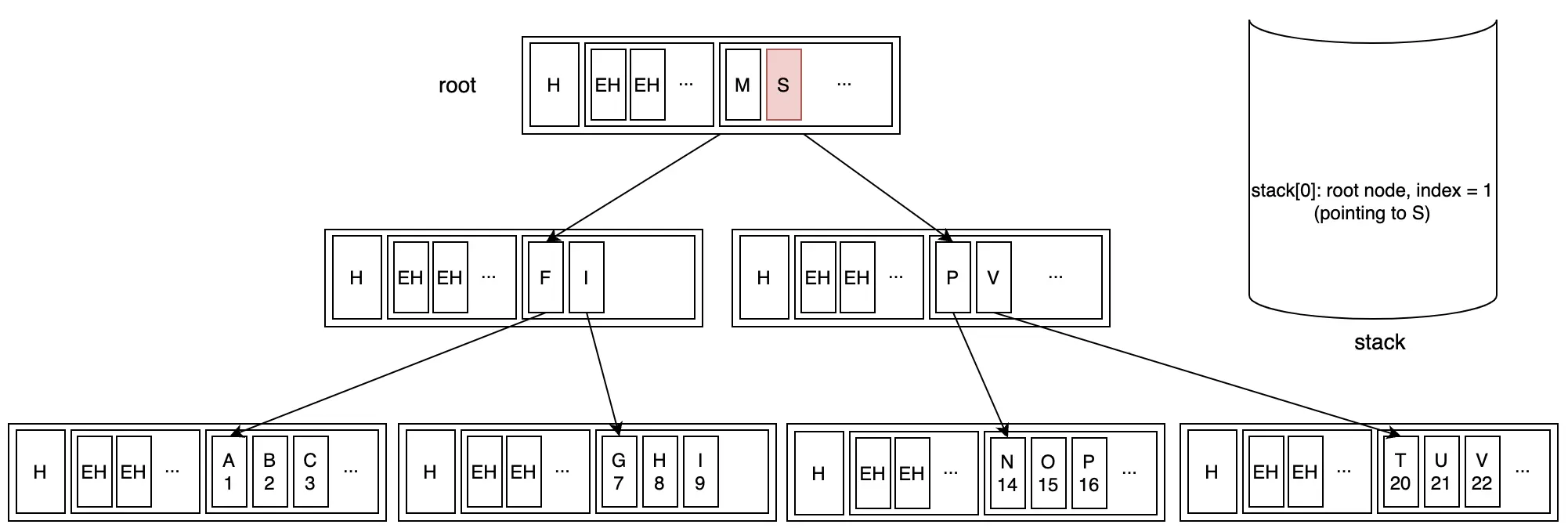
Bước 2: Di chuyển xuống branch node và tiếp tục tìm kiếm nhị phân
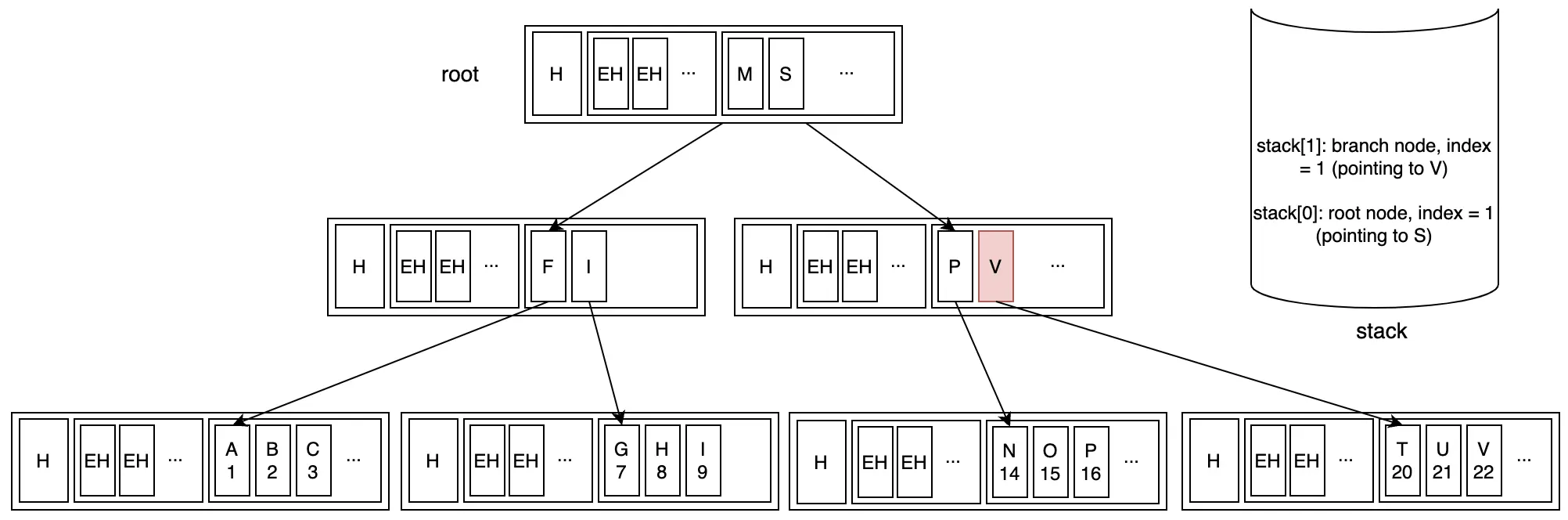
Bước 3: Cuối cùng đến leaf node và tìm thấy key "V"
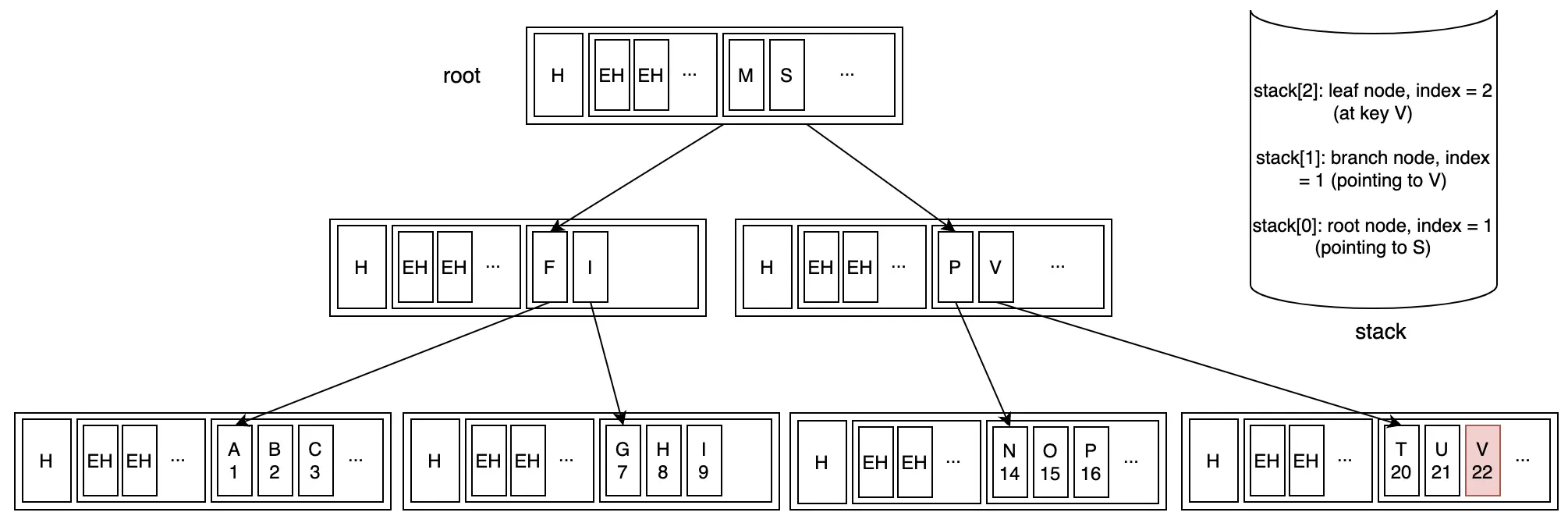
Ta tốn log(C) cho mỗi lần tìm kiếm key ở từng node, ta cần duyệt qua log(N) node như vậy để từ root có thể xuống tới leaf node. Vậy độ phức tạp thời gian của toàn bộ quá trình tìm kiếm sẽ là O(log(C)log(N)).
Kết
Vậy là ta đã tìm hiểu được cách thức hoạt động của Cursor. Cursor cho phép ta navigate qua data một cách hiệu quả, có thể scan ranges, iterate qua keys theo thứ tự… Nhưng điều gì xảy ra khi có nhiều operations đồng thời trên cùng một database? Ví dụ: một goroutine đang đọc data qua cursor, trong khi goroutine khác đang update/delete keys?
Nếu không có mechanism nào kiểm soát, ta sẽ gặp những vấn đề kinh điển: dirty reads, inconsistent data, race conditions. Đây chính là lúc Transaction System trở nên cực kỳ quan trọng. Và tất nhiên rồi, hẹn bài sau nhé hihi.