- Published at
Build một cái K-V Database đơn giản như thế nào?

Hành trình tìm hiểu cách xây dựng một K-V Database đơn giản từ code thực tế
Table of Contents
Hi mọi người, chuyện là mình vừa xong đồ án tốt nghiệp và chỉ đang chờ ngày tốt nghiệp thôi nên cũng có kha khá thời gian rảnh đâm ra ngứa tay (lưu luyến sự bận bịu của đồ án tốt nghiệp chăng???). Mò lại trong đống list note ngày xưa thì thấy là mình có đang thắc mắc rằng 1 cái Key-Value (K-V) Database thì nó được xây dựng chuẩn chỉ từ code như nào thay vì chỉ là lý thuyết (cái này chắc lưu lạc từ hồi mình mò vọc vạch Raft). Mình cảm thấy việc hiểu concept có vẻ là chưa đủ lắm, nó chỉ quan sát từ bên ngoài chứ thật sự không biết bên trong nó diễn ra như nào. Thôi thì cũng rảnh mà, đọc xem thử giữa triển khai thực tế và lý thuyết nó có khác gì nhau không. Biết đâu sau này mình lại trở thành contributor với một thứ ma quỷ gì đó thì sao =))))
Không lòng vòng nữa, let’s gồ.
Problem: Lưu một mớ thứ theo dạng Key-Value sao cho hiệu quả?
Đơn giản, tạo một cái Hash Map là xong. Nhưng dễ ăn vậy thì người ta đã không tạo ra mấy cái K-V Database làm gì. Vậy thì những vấn đề có thể gặp phải thường là gì:
- Lưu vài triệu hay cả trăm triệu K-V có hiệu quả không?
- Cần phải đọc/ghi đồng thời một cách an toàn thì sao?
- DB crash thì có oẳng luôn data không?
Mấy cái vấn đề trên nghe có vẻ vĩ mô, nhưng mà có vĩ mô thì mới có nhiều giải pháp hay. Tất nhiên mình không thể nào có khả năng tự build một cái DB xịn xò như vậy được, nó cần lượng kiến thức rất lớn về OS, các kĩ thuật nâng cao khác mà mình chưa tiếp xúc bao giờ. Vậy thì làm sao để biết cách build? Đơn giản, cái gì khó thì mình học thôi, nên là mình sẽ đi đọc mã nguồn của một cái K-V Database để xem nó được xây dựng như thế nào. Ở đây ta chỉ quan tâm đến On-disk K-V Database nên tạm bỏ qua những cái như Redis nha.
Với K-V Database, có 2 storage engine architecture phổ biến nhất thường là B+ Tree (LMDB, SQLite) và Log-Structure Merge Tree (LevelDB, RocksDB). Cách tiếp cận triển khai LSM Tree không được đơn giản lắm (coi như để dành bài sau đi nếu có cơ hội, tại mình cũng tính vọc thằng Badger để nghịch tí). Thế nên là rẽ nhánh qua B+ Tree với LMDB, nhưng LMDB code bằng C thì nâng cao quá rồi, bó tay. Mình chọn Bolt (Một phiên bản implement LMDB nhưng được code = Go) vì có vẻ nó phù hợp vì nó nhỏ vừa đủ để hiểu, vừa dễ tiếp cận.
Bolt được sử dụng bởi các project lớn như etcd trong Kubernetes (tuy nhiên đây là bản đã được team etcd fork về và tiếp tục maintain, mã nguồn mình tham khảo trong series này sẽ là mã nguồn gốc của tác giả), Consul, NATS và nhiều Go applications khác. Nó nổi tiếng với sự đơn giản khi chỉ khoảng 3k LOC (pure go), hỗ trợ ACID transactions với zero data loss.
Các thành phần chính cần thiết
Ta có thể mô tả chung kiến trúc của Bolt khi mà ứng dụng tương tác như hình sau:
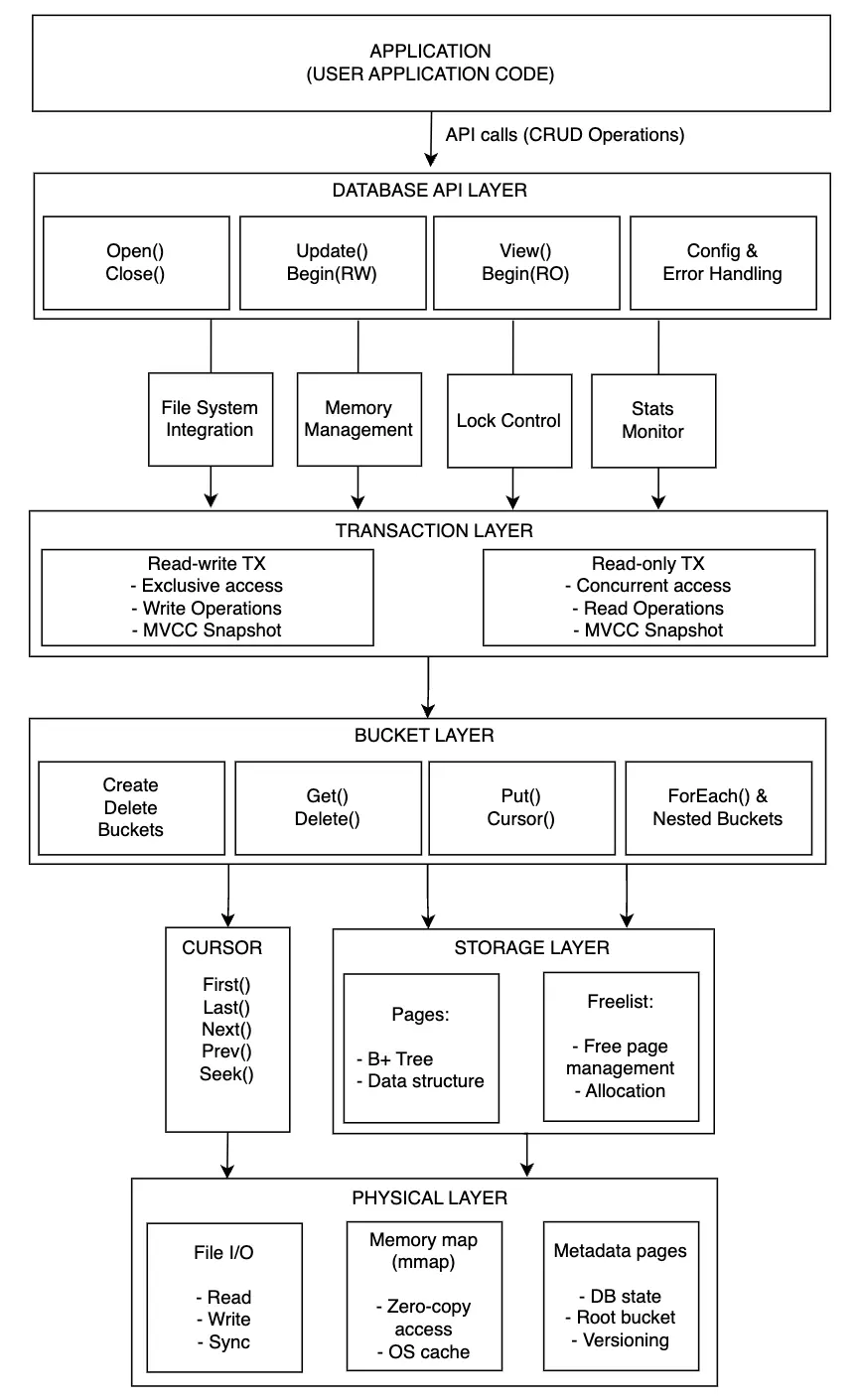
Mỗi thành phần mình sẽ thảo luận riêng thành 1 bài luôn cho dễ đọc, đọc theo kiểu top-down hay bottom-up cũng được nhưng style mình viết thì là bottom-up, mọi người nhấn vào từng bài để đọc nhé
- P1 - Database file format
- P2 - Storage and cache management
- P3 - Data structure
- P4 - Bucket System
- P5 - Cursor
- P6 - Transaction system
- P7 - DB Layer
Sneak peek
Cuối series, bạn sẽ hiểu tại sao đoạn code này nhìn nhỏ nhưng lại có võ:
db.Update(func(tx *bolt.Tx) error {
bucket := tx.Bucket([]byte("users"))
return bucket.Put([]byte("john"), []byte("developer"))
})